


Data Engineering Digest, March 2024

Hello Data Engineers,
Welcome back to another edition of the data engineering digest - a monthly newsletter containing updates, inspiration, and insights from the community.
Here are a few things that happened this month in the community:
The most popular open-source stacks used in production.
The pros and cons of transforming in Power BI.
An amazing list of Python libraries that data engineers love!
Subqueries vs CTEs.
What’s the most challenging task in modern data engineering?
Application side or database side - where to store biz logic?
Community Discussions
Here are the top posts you may have missed:
1. What's your prod, open source stack?
Looking into creating an open source ELT stack from scratch: if you have one, or have had one that worked well, what were the stack components?
It’s no secret that data engineers love open-source tooling for their ability to get started for free and greater flexibility over implementation. Finding open-source tools that are production ready is a bit more challenging and it’s often a game of watching who else is using it in production for validation.
💡 Key Insight
Python and Postgres were the most commonly mentioned tools because they can cover most DE use cases and they simply work really well. Some of the other popular open-source tools mentioned were:
Ingestion: Meltano
Transformation: dbt, Spark
Workflow Orchestration: Airflow, Dagster, Mage
Real-time: Kafka, Debezium
Infrastructure & Containers: Terraform, Docker, Kubernetes
Visualization: Superset, Streamlit, Metabase
One member also shared a list of all of the (mostly) open-source tools that AirBnb uses.
2. Should Power BI be used to extensively transform incoming data?
One member shared that a department at their company has been importing raw data into Power BI and using it exclusively for transformation and then analytics. They are concerned that the users are not using best practices and took this approach because they lack expertise in data analytics and data engineering. Is this actually common practice or is it something to be concerned about?
If you’re a data engineer who is involved in analytics then you’re probably leaning towards “no” but as always there are some trade offs to consider and probably a middle ground here.

💡 Key Insight
Most data visualization tools allow you to do lightweight transformations in the tool itself and often have other sticky features baked in such as an inline database to store your data and the ability to create a semantic layer or define metrics. It should come as no surprise as it’s in the best interest of these companies because it makes it more difficult to move off and empowers more users (who may or may not be using best practices) to quickly build on their platform.
As
recently put it:Low-code solutions help you develop workflows faster and they also can help make bad decisions faster.
In an ideal world, members agree that data visualization tools like Power BI should be focused on presenting data, not transforming it. Data engineers would prefer to have data be efficiently transformed, tested, and stored in a way that is scalable and easy to maintain. In the real world, if you aren’t delivering value fast enough then stakeholders are going to circumvent your best practices to get their own job done. The best engineers understand this dynamic and should put some guard rails in place but be comfortable with a bit of flexibility to allow users to answer their own ad-hoc questions.
One interesting framework we’ve been reading about that may help with self-serve is the concept of dashboard trees: How Dashboard Trees Work and Why.
3. Favorite Python library?
What is your favorite Python library and why?
There is a lot of activity right now with new tools/libraries that are improving workflows for data engineers. We found a few classics as well as a few lesser known ones that look very interesting.
💡 Key Insight
We organized the answers into a list of the most popular answers by category:
APIs
Requests - A simple, yet elegant, HTTP library.
HTTPX - The next generation HTTP client.
Tenacity - Retrying library for Python.
FastAPI - FastAPI framework, high performance, easy to learn, fast to code, ready for production.
Litestar - Effortlessly build performant APIs.
asyncio (built-in) - a library to write concurrent code using the async/await syntax.
File/Operating System Management
os (built-in) - Miscellaneous operating system interfaces.
pathlib (built-in) - Object-oriented filesystem paths.
Watchdog - Python API and shell utilities to monitor file system events.
Typing & Testing
Pydantic - Data validation using Python type hints.
pytest - The pytest framework makes it easy to write small tests, yet scales to support complex functional testing.
Data Visualization/Data Applications
Streamlit - A faster way to build and share data apps.
Ploty-Dash - Data Apps & Dashboards for Python. No JavaScript Required.
Utilities & Other
tqdm - A Fast, Extensible Progress Bar for Python and CLI.
Functools (built-in) - Higher-order functions and operations on callable objects.
Toolz - A functional standard library for Python.
SQLAlchemy - The Python SQL Toolkit and Object Relational Mapper.
Typer - Typer, build great CLIs. Easy to code. Based on Python type hints.
Loguru - Python logging made (stupidly) simple.
4. Subqueries vs CTE, what’s your preference?
Subqueries and Common Table Expressions (CTEs) in SQL are both used for getting a subset of data and manipulating it to be used elsewhere in a query but they are also typically interchangeable so what’s the difference and when should you use one vs the other?
💡 Key Insight
Snippet from our SQL Guide: CTE vs Subquery:
CTE
Can be used multiple times in the body of a query.
Allows for recursive queries.
Generally more readable.
Subquery
Can only be used once in a query.
Can be used to filter results in the WHERE clause.
Can be used as a column in your query.
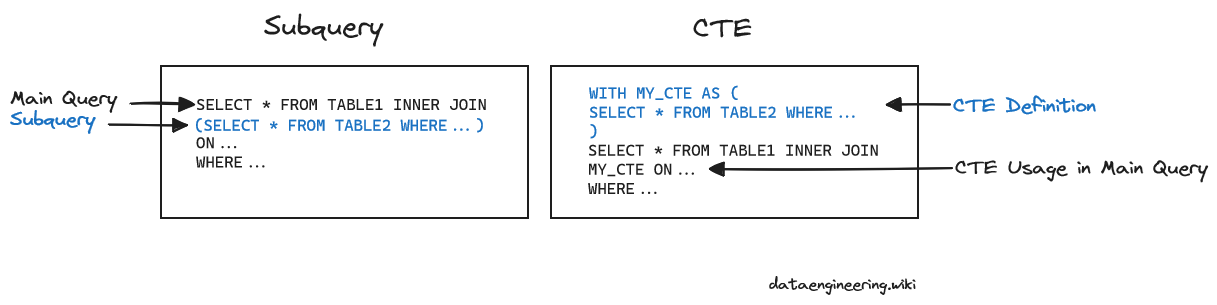
When comparing subqueries to CTEs, most data engineers typically choose CTEs because they allow you to break down queries and increase readability and maintainability. In the past on certain databases there were performance differences but most current versions of databases are able to optimize both to get similar performance. In general, database engines are very good at optimizing performance because they’ve been around for decades and most of the time just making your SQL readable is all you need to do.
Still, you still want to avoid making CTEs too complicated and consider moving reusable CTEs into staging tables instead. Others mentioned you can sometimes get better performance with a temp table vs a CTE because a query optimizer can use statistics on temp tables or you can index them to help the optimizer create a better query plan. As always, use this advice as a general rule of thumb but always test your assumptions!
5. As a data engineer, what do you find the most challenging task in modern data engineering?
💡 Key Insight
The #1 challenge data engineers are currently facing is managing stakeholder expectations. There are several factors that feed into this problem such as a lack of data literacy / data-driven culture, the data team being resource constrained, and interpreting the underlying problem the stakeholder is communicating. These challenges are not technical but cultural and building a data culture is often a war of attrition that requires collaborating with leadership to set expectations and get buy-in vs a grassroots approach.
Some of the other challenges mentioned were:
Lack of control over data source quality/reliability.
DE having an unclear understanding of the business problems.
Constantly having to justify data value and investing in data infrastructure.
Too many tools to know/continuous learning and adaptation.
When the stakeholder with unrealistic expectations is your boss/leadership.
It’s interesting that creating robust and reliable data pipelines was not really mentioned as a challenge. It could be a sign of data engineering moving up the value chain from making data pipelines to focusing on unlocking the value from their data.
6. DBMS vs Java
This discussion was about whether or not it’s better to keep business logic inside an application (in this case Java-based) or store it within the database itself. The author (a data analyst) had suggested using a stored procedure to complete the task and their suggestion was disregarded by their team’s developers.
It’s common for junior data professionals to question the reasoning behind the existence of multiple parts to their company’s data processes. For example, having multiple environments (development, staging, production), the existence of scheduling scripts and test databases, unit tests, and CI/CD can seem cumbersome and unnecessarily complicated. However, the way these questions are handled is just as important for senior engineers to get right as it is for juniors to understand the why.
💡 Key Insight
First, let’s take a moment to reflect on how the situation could have been handled differently. This discussion emphasizes the importance of effective mentorship for more inexperienced colleagues - it’s not enough to say “stay in your lane” or “because I said so, do your research”. Providing clear pros/cons and real life examples of why the processes are in place can be crucial for ensuring compliance and buy-in.
For this particular situation, explaining how stored procedures are harder to maintain than Java code for code reviews and updates, difficulties in testing code and continuous code development/deployment (would require a test database), and changes to database schemas needing changes to stored procedures would have been far more helpful.
That being said, there are valid reasons to consider a DBMS-centered approach, namely it being more efficient and not requiring any networking hurdles being major pros. In reality, the “best” solution depends on how critical the data is and how often the schema will change. Still, when considering the importance and need for testing, most users did settle on code-based ETL being the superior approach.
🎁 Bonus:
☁️ Tips for passing DP-203 without any prior cloud experience
💥 I created an open-source microsite to help analysts and SQL-heavy devs get started with Spark
📅 Upcoming Events
4/8-4/12: MDS Fest (Virtual)
Share an event with the community here or view the full calendar
Opportunities to get involved:
Share your story on how you got started in DE
Want to get involved in the community? Sign up here.
What did you think of today’s newsletter?
Your feedback helps us deliver the best newsletter possible.
If you are reading this and are not subscribed, subscribe here.
Want more Data Engineering? Join our community.
Want to contribute? Learn how you can get involved.
Stay tuned next month for more updates, and thanks for being a part of the Data Engineering community.
Thanks! I was just about to go looking for something to handle retries. I’ll check out Tenacity.