


Data Engineering Digest, May 2024

Hello Data Engineers,
Welcome back to another edition of the data engineering digest - a monthly newsletter containing updates, inspiration, and insights from the community.
Here are a few things that happened this month in the community:
SQL vs. Python: When should you use each?
Discussing data lineage tools.
Can DuckDB sink or fly as a data warehouse?
Dimensional or 3NF? Decoding data modeling techniques. 🧩
Kimball in the cloud age - still relevant? ☁️
The best dbt alternatives so far in 2024.
Community Discussions
Here are the top posts you may have missed:
1. When do you prefer SQL or Python for Data Engineering?
Determining when to use SQL vs Python (or any other general programming language) isn’t always clear and it’s not easy to find a clear answer to this question. We often hear people say to “use the right tool for the job” without elaborating on where that line lies. Well, this month we finally received some specific answers to this question.
💡 Key Insight
Here is the summary of the breakdown from the community:
Data engineers typically use Python when…
Ingesting or moving data to/from data storage (databases, blob storage, etc.)
For example: Ingesting data from APIs and manipulating data in files.
Transforming data in SQL would be very complex. Complexity can be subjective but if it starts to feel frustrating in SQL that may be a good indicator to reevaluate your tool. You may have noticed that modern cloud data warehouses allow you to write Python UDFs for situations like this.
Some examples included: One-hot-encoding, string manipulation, mathematics, date parsing/other type coercion, and event-driven state machines such as in funnel analysis.
There is a specialized library that would save time for a particular use case. For example Numpy or scikit-learn for machine learning.
Data engineers typically use SQL when…
Transforming data or otherwise working inside SQL-compatible data storage.
For example: Relational databases (e.g. PostgreSQL, MySQL, SQL Server) or cloud data warehouses (e.g. BigQuery, Redshift, Snowflake).
Let’s first start by reiterating that this isn’t an either or question. Data engineers often use a combination of both SQL and Python to leverage the strengths of each language for different aspects of data engineering tasks. As it relates to building data pipelines, generally speaking, Python is used outside of the parts that involve the database and SQL is generally used inside for data transformation. There are also real-world considerations like what your team is most comfortable with or already using.
Focusing in on the transformation step, Python can still have a role to play here but the vast majority of the time SQL is a better choice because it’s optimized for that workload.
One member shared an anecdote highlighting this:
I've seen people load whole tables in Panda Dataframes and then doing filtering/joining.
"Uuhhh, you probably want to put that in your select statement". All of a sudden a script runs in 4 seconds instead of 7 minutes.
Related discussion: When not to use SQL
2. Data lineage tools

If you aren’t familiar with the term, data lineage is the process of tracking how data flows through a data pipeline to give you a clear picture of where it came from and where it’s being used. The reason we as data engineers care about data lineage is because it’s a very useful type of visual documentation which allows us to quickly identify issues in pipelines and understand the impacts when a pipeline breaks.
💡 Key Insight
Here are the top recommended data lineage tools (free unless specified otherwise):
Open Lineage: A linux foundation project that proposes an open standard and API for lineage collection. It can be used in combination with another LF project, Marquez, to visualize the metadata.
dbt: A tool that applies software engineering practices to transforming data with SQL. It comes with a built-in lineage view which is powerful but won’t be able to show any pipelines that live outside of dbt. Has managed offerings as well.
SQL Lineage: A SQL lineage analysis tool powered by Python. Similar to dbt lineage.
DataHub: Originally built at LinkedIn and then open-sourced, DataHub markets itself as a full metadata platform allowing you to collaborate and enrich the metadata around your data assets. Has managed offerings as well.
Informatica Data Catalog (paid): One offering by Informatica is an AI-powered data catalog and metadata management platform. Similar to DataHub in terms of features and functionality.
Open Metadata: A unified platform for discovery, observability, and governance powered by a central metadata repository, in-depth lineage, and seamless team collaboration.
One difficulty that engineers pointed out with open-source data lineage tools is that it can be difficult to find tools that support all of the integrations you need. The paid offerings tend to support more integrations.
3. DuckDB as a warehousing solution.
We’ve discussed DuckDB a few times before (links below). This month the community wants to know, can you use it for a data warehouse?
Related reading: What’s the hype with DuckDB now? and Views on using duckdb + S3 as a datalake?
💡 Key Insight
DuckDB by itself is limited in a few ways that would make it an ill-suited choice for a traditional data warehouse workload.
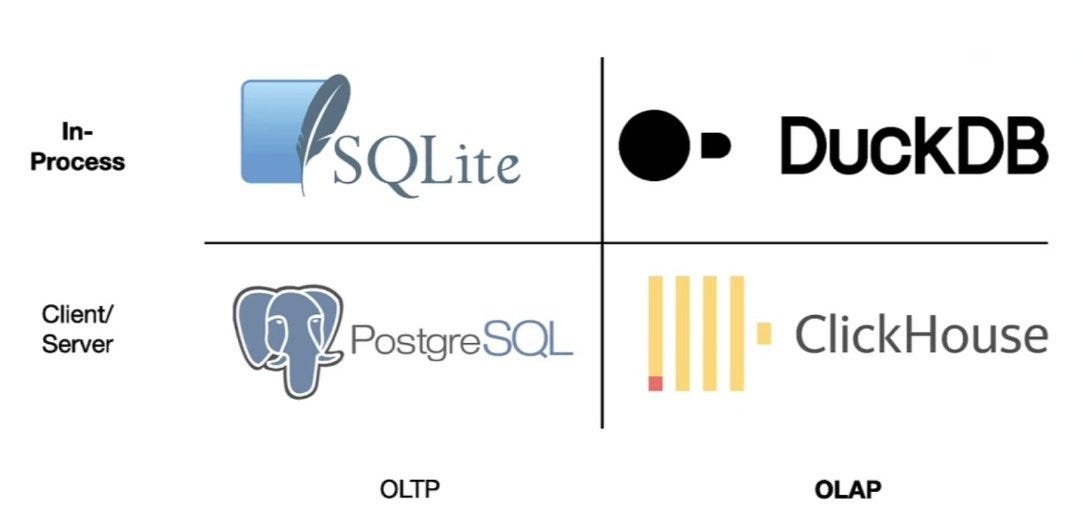
Designed to be embedded. This first limitation is more of a hint at the use-cases DuckDB is targeting. DuckDB uses an in-process deployment model which in simple terms means it’s meant to be embedded in an application. There is no separate server for the database - it lives where your application logic lives. This enables data transfer within the same memory address space which eliminates the need to copy large amounts of data over sockets and results in improved performance.
There is no separate server for the database - it lives where your application logic lives.
Concurrency limitations. Either one process can read/write to the database OR multiple processes can read from the database but no processes can write. Any transactions that modify the same rows at the same time will cause an error OR you manage transaction locks yourself in application logic.
The general community sentiment around DuckDB is:
It’s better for read-intensive and low-concurrency workloads (e.g. embedded analytics or local analytics).
It does not come with many features a traditional data warehouse would come with such as backup/restore, snapshots, RBAC, and other data governance features.
While DuckDB may not be the top choice for a data warehouse it is an excellent tool for prototyping and sometimes in data pipelines as well.
MotherDuck is a company that is working to solve these limitations by building on top off and extending DuckDB to create a serverless warehouse offering.
4. Dimensional vs 3NF Data Models
In my organization we often debate the benefits of 3NF vs Dimensional in terms of how we should model our data outcomes. I do not want to taint this post with my opinion -- I am curious about yours. What data models style does your organization use and what is your experience with both types?
Data modeling is a bit of a lost art but it’s making a resurgence recently in the community discourse. There are several data modeling techniques for different scenarios but dimensional modeling and 3rd Normal Form (a normalization concept in relational modeling) are among the most popular. Choosing the right data modeling techniques to use is a crucial skill for data engineers to master for performance, cost optimization, and reducing cognitive load on end users.
💡 Key Insight
From "The Data Warehouse Toolkit" By Ralph Kimball and Margy Ross:
Normalized 3NF structures are immensely useful in operational processing because an update or insert transaction touches the database in only one place. Normalized models, however, are too complicated for BI queries. Users can’t understand, navigate, or remember normalized models that resemble a map of the Los Angeles freeway system. Likewise, most relational database management systems can’t efficiently query a normalized model; the complexity of users’ unpredictable queries overwhelms the database optimizers, resulting in disastrous query performance. The use of normalized modeling in the DW/BI presentation area defeats the intuitive and high-performance retrieval of data. Fortunately, dimensional modeling addresses the problem of overly complex schemas in the presentation area.
🤓 Tip: Discover The Data Warehouse Toolkit and other recommended data modeling learning resources.
Dimensional modeling (Kimball modeling, star schema):
Enables faster query performance for analytical (OLAP) workloads such as reporting and visualizations.
Structures data into facts and dimensions which can be easier for non-technical users to understand and work with (lower cognitive load).
Typically used in data warehousing on column-oriented databases.
Think select/aggregations on large sets of data.
Relational Modeling:
Commonly used for transactional (OLTP) workloads such as in software applications for credit card payments, online bookings, and record keeping where data integrity and accuracy are crucial.
3NF is most commonly used in relational modeling but you can go higher or lower in normalization.
Typically used in operational applications on row-oriented databases.
Think insert/update/delete on small sets of data at a time.
5. How much of Kimball is relevant today in the age of columnar cloud databases?
Another back-to-back data modeling question! This one is focused on dimensional modeling but related to the discussion above.
The community member that posted this question wonders how much we still need Kimball (dimensional modeling) given the fact that other techniques like One Big Table (OBT) can outperform a dimensional model on column-oriented databases like Big Query. They specifically cited a blog post from Fivetran “Data warehouse modeling: Star schema vs. OBT” where using the OBT technique improved query times significantly.
In the age of columnar cloud databases like BigQuery, it’s no surprise that data engineers are reassessing traditional data modeling approaches such as those advocated by Kimball.
Recommended reading: Is Dimensional Modeling Still Relevant? By Margy Ross
💡 Key Insight
Dimensional modeling has been around since the 1980s and is still widely used due to the timeless advice within it despite technological advances and cheaper resources. The star schema is just one part of the overall strategy which is focused on the lifecycle of a data warehousing project.
Data engineers shared that one of the main reasons they still use dimensional modeling is because of how it makes it easier for end users to reason about and use the data.
Think about your data model as being a public interface no different than an API or a function. It’s important that your interface is clean and most importantly makes sense to the business users.
In other words, if it’s overly complicated then it won’t get used! This is a good reminder that performance is only one concern data engineers must evaluate against. What is and always be the top priority is delivering value to the business.
Ultimately, the “best” data modeling approach for a modern, column storage cloud-based data warehouse like BigQuery is typically a combination of techniques tailored to the specific requirements of the organization. For example, you may start with OBT to deliver value quickly while you build a dimensional model behind it and deprecate unnecessary denormalized tables over time.
Tip: If you plan to read The Data Warehouse Toolkit, check out this reading guide which covers which parts are relevant and which you can probably skip.
6. Alternatives to dbt-core and dbt cloud?
Curious to hear what others used before migrating to (or use after migrating from) dbt-core / dbt cloud?
dbt is a popular tool among data engineers due to solving many of the problems that once plagued sql analysts/engineers - namely the ability to track data lineage, use version control for SQL, integrate better testing/documentation, etc. Newer dbt alternatives are working to compete by reducing costs, improving performance, and carving niches to suit particular workflows more naturally.
💡 Key Insight
SQLMesh: Efficient data transformation and modeling framework that is backwards compatible with dbt.
Self documenting queries using native SQL Comments
Ability to plan / apply changes similar to Terraform to understand potential impact of changes.
Column-level lineage!
Unit testing, audits, and compile-time error checking.
SDF: A SQL engine and data transformation tool. It ingests data, metadata, and SQL statements to validate business logic, execute queries, and enforce policies.
SDF claims to be significantly faster than dbt in terms of run and compile time performance.
Related to above, it also comes with compile-time error checking.
Comes with a built-in query engine and data governance features for data quality and PII.
While not yet open-source, SDF is expected to release an open-source version in the near future.
Lea (BigQuery Specific): A minimalist alternative to dbt.
Dataform Core (BigQuery specific):
Similar features to dbt core.
🎁 Bonus:
📅 Upcoming Events
6/13: Trino Fest 2024
Share an event with the community here or view the full calendar
Opportunities to get involved:
Share your story on how you got started in DE
Want to get involved in the community? Sign up here.
What did you think of today’s newsletter?
Your feedback helps us deliver the best newsletter possible.
If you are reading this and are not subscribed, subscribe here.
Want more Data Engineering? Join our community.
Want to contribute? Learn how you can get involved.
Stay tuned next month for more updates, and thanks for being a part of the Data Engineering community.