
Data Engineering Digest, April 2023

Hello Data Engineers,
Welcome to the first edition of the data engineering digest - a monthly newsletter containing updates, inspiration, and insights from the community.
Here are a few things that happened this month in the community:
Spark and Databricks seem amazing - what are the downsides?
The community discusses a spicy takedown of the modern data stack.
The top ways Data Engineers are using ChatGPT in their day jobs.
Is the Data Mesh paradigm really practical?
How do Data Engineers build custom connectors?
What is all of the fuss with DuckDB?
Community Discussions
Here are the top posts you may have missed:
1. Spark/databricks seems amazing?
If you’re building a data platform right now, Spark + a data lake architecture seems like a very attractive option for anyone dealing with large volumes of data. Databricks is a popular managed version of this setup but there is always a tradeoff and it’s not always obvious.
“Spark as a compute engine with its different APIs seems extremely powerful. What are the drawbacks? If self-hosting, I guess it's what comes with self-hosting anything. If using a managed service like Databricks, I guess it's the cost?”
When you’re building a new data platform and comparing which tools and architecture to use, you want to be sure you understand the tradeoffs before investing time, money, and energy into building it.
Some of the challenges engineers face when making comparisons between tools are:
There are dozens of new tools emerging each year.
Not all tools are forthright about their downsides (you can use it for everything!! 🤪).
It takes time to learn the ins and outs of each tool making it hard to find reviews where someone has spent significant time in both tools being compared.
Luckily, with most cloud and SaaS offerings these days the upfront financial investment can be mitigated but that doesn’t stop surprises from happening...
💡 Key Insight
Generally, the sentiment for Spark as a compute engine is very high in the community, and having Spark opens up a lot of flexibility and use cases. People also generally believe that Databricks makes it easier to manage Spark with their data lake/lakehouse and instead focus on providing business value vs managing infrastructure.
That being said, the Databricks notebook workflow isn’t everyone’s favorite way to work and some members complained that it’s hard to productionize and debug. Others have pointed out that Databricks has improved parts of their platform, specifically their workflows feature which can orchestrate data pipelines natively instead of using an external workflow orchestration tool like Airflow.
Some engineers warned that running Spark (self-managed) can be more difficult because of the higher learning curve and difficulty to run it efficiently. Overall, if you need a data lake and you have a smaller team then it might make sense to use Databricks. If you have a larger team (and presumably lots of data/need for high performance) it might make more sense to run Spark yourself and fine-tune it for performance as well as not have to pay Databricks the overhead.
One commenter pointed out a question we should probably ask ourselves more often first. Do we even have the scale of data where we would need distributed processing? At most companies, Spark is probably overkill.
2. The roast of the modern data stack?

A blog post roasting the “modern data stack” made the rounds this month as members seemed put off by the author’s writing style but still found some insightful information in it.
“She's really angry, but she makes me think, and that's probably a good thing?”
Here’s an excerpt from the original article titled: “Customer Empathy is Dead”:
”MotherDuck can’t be the antidote to Databricks and Snowflake overspend because it’s backed by the same financiers who have billions riding on taking Databricks public or to an acquisition and it’s backed by the same financiers who own billions in Snowflake stock. Why would they place a serious bet against their much, much, much more significant positions? They won’t. Not now, not soon, and not in the foreseeable future. So MotherDuck can’t actually take meaningful workflows away from Databricks and Snowflake.”
It’s worth noting that MotherDuck is not the team creating the FOSS DuckDB, DuckDB Labs is. MotherDuck appears to be in partnership with DuckDB Labs and seems to be working on a managed version of DuckDB. MotherDuck was separately in the news recently for their own controversial article titled “Big data is dead.”
The “modern data stack” is a marketing term for a set of tools that are cloud-based, easier to use, lower cost of entry, and time saving vs the “legacy data stack” which refers to hosting your own infrastructure and using older tools. While it promises to solve many of the problems data teams have, many question the value they are actually getting and the overhead of using a dozen different tools to solve their problems.
💡 Key Insight
The article being discussed was about several SaaS companies and their products that have become mainstream in the marketplace. The author points out that several of them are backed by the same VCs, likely because they complement the other companies in the VC’s portfolio.
The thing to be wary of in the modern data stack is that while it can make parts of the data engineer's job easier, we can’t forget about the end value to the business. Data engineers need to always be tracking the business value and not let data sprawl get out of control. Several members shared the sentiment that while some of the modern data stack tooling reduces friction, it can also make it easier for costs and mismanagement to get out of control.
3. How has ChatGPT helped you in your DE job? First hand experience only, plz.
How are data engineers using ChatGPT and generative AI to help them in their job?
“We're already accustomed to hearing people say this is how YOU should use chatGPT, but I rarely see people say This is how I use chat gpt."
Luckily, several members shared their first-hand experiences of how they are and aren’t using ChatGPT for work.
There have been many discussions in the community recently about ChatGPT and questions about if it’s going to replace data engineers or if it can help make their lives easier. Just like in many other professions right now, people are looking around at each other to try and gauge the sentiment and potential threat of this new tool. If it’s not going to replace you and it can even help you with your job, that could be a huge advantage to the data engineers who learn how to use it effectively.
💡 Key Insight
Overall, the top ways members said they are using ChatGPT/generative AI are:
Writing boilerplate code
Writing documentation/comments
Helping with regex
As an alternative to searching StackOverflow/Google
Several people warned against putting company code or data into it, likely because of the fear that ChatGPT could be trained on their or their company’s sensitive information. Folks also shared that ChatGPT’s usefulness is limited because it can often give incorrect answers and you have to have enough experience to tell when it’s leading you astray or do lots of research which would nullify most of the time-saving benefits. Overall, ChatGPT is saving data engineers some time but it doesn’t seem like it will be replacing us…yet.
4. Data Mesh
The data mesh concept is something that has come up in discussions and blog posts but people are still left confused as to what it is, what its value is, and if anyone is actually implementing it in their organization.
“I know there would have been many discussions on this before, but being new to the field and going to work as a Data engineer now soon, I wanted to know is there any value in the concept of Data Mesh? Is it the next big thing? Or is this paradigm shift currently being used in the industry already?”
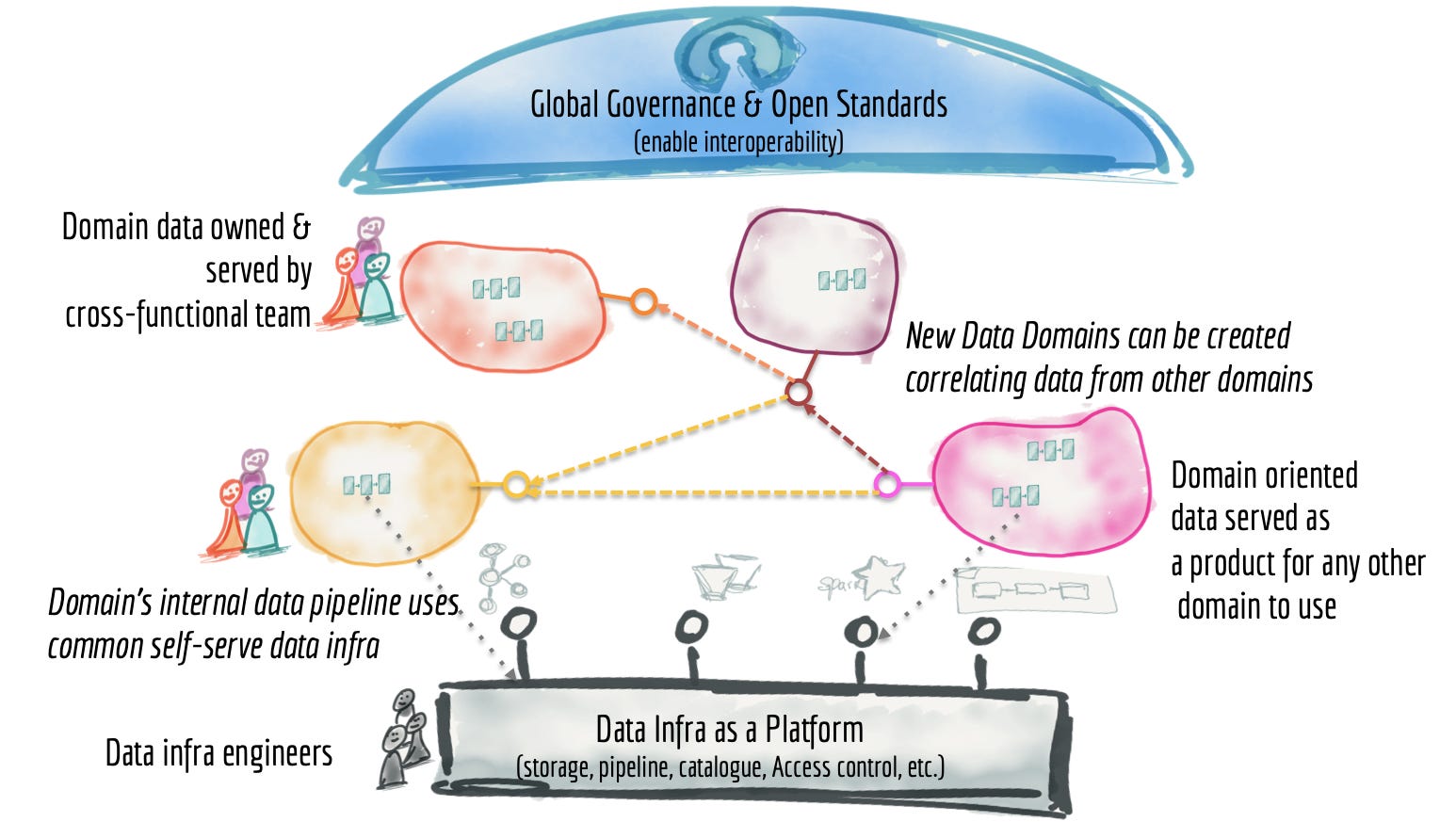
The data mesh is a newer data architecture concept that has been widely discussed over the past few years and popularized from the article “How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh”. A data mesh is primarily an organizational change where instead of having one centralized data team, you have a data engineer in each business domain and then a smaller centralized team that builds and maintains the foundation which the other teams use. Each domain team then focuses on building data products and APIs for the rest of the organization to use. The data mesh has been proposed as a solution to scaling data teams as a company becomes larger and more complex.
💡 Key Insight
While a few companies have successfully gotten the data mesh to work, it seems like it’s not practical for most companies because of the cost of having multiple data teams and the need for a strong and centralized data platform team.
A few criticisms of the data mesh that people mentioned were that information silos still exist and that the decentralized approach made ownership of shared assets (tables, pipelines, etc) harder to manage.
5. Data Pipelines - how do you build data pipelines for sources not available in today’s ELT tools (Fivetran, Talend, Airbyte)? Old fashioned scripts and YOLO?
There are several connector SaaS tools to choose from these days which is appealing to data teams for increasing the speed of connecting to new data sources. However, some of the open-core platforms only maintain a handful of connectors themselves and rely on the community to maintain the other open-source connectors they use.
Since there will always be the need to create a custom data connector, how do data engineers do that today and what are some tips/best practices?
Building and maintaining custom code is often a burden to data teams due to data sources constantly changing and the knowledge or capacity to build a custom connector/script well in the first place. Still, it’s a necessary skill that many data engineers need to know because even with managed solutions in place, there are always new data sources emerging, and sometimes engineers need to customize an existing solution to fit their needs.
💡 Key Insight
If you are going to write your own connector, you can avoid some headaches by using software engineering best practices like implementing strong observability, testing, automated deployment, alerting, and documentation. Python was what most people use for building their own custom scripts orchestrated with Airflow or Dagster.
If you’re going to use a paid connector SaaS, one insight from the community is that while these tools can be helpful, they can also become very expensive to scale and at a certain point it might make more sense to manage the connectors in-house. This is because many of these managed tools are priced based on data volume or the # of rows that have changed. That being said, engineers also typically agree that building and maintaining data connectors isn’t usually considered high-value work and you do want to offload the maintenance if you can.
6. [Out of the Loop] What’s the hype with DuckDB now?
DuckDB has quickly built up a following over the past few years leaving at least one data engineer confused about the hype.
“I’ve seen many posts here mentioning it [DuckDB]. I think it’s a different approach but what’s its leverage against a stack built around BigQuery or plain Postgres for example?”
Jupyter notebooks running Python with a slew of analytics packages (pandas, matplotlib, etc.) are the current standard for data engineers trying to quickly get an exploratory analysis piece up and running. DuckDB is being used by some engineers as a way to quickly do analytics/transformations vs Pandas or Polars.
DuckDB is an in-process OLAP db that allows data engineers to run analytics workloads against larger datasets on a single machine. DuckDB has been compared to SQLite (lightweight/local transactional db) but for analytics.
💡 Key Insight
Data engineers are using DuckDB in several different ways:
As a local data warehouse
Embedding it into an app for faster analytics
As part of their CI/CD
For processing/transforming large datasets that can’t fit into Pandas memory, but aren’t quite at the size that requires distributed processing like Spark.
So far, data engineers love that they can just use SQL, that it has several convenience features (like pointing to an S3 url instead of downloading data locally first), and the fact that you can use it on a server and not have to pay additional costs for data scans.
One callout from an engineer is that DuckDB does not natively support many of the data lake/table formats (Apache Iceberg, Apache Hudi, and Delta Lake).
🎁 Bonus:
😴 i just want sleep (remember to take time and relax)
📝 Step-by-step tutorial: Building a Kimball dimensional model with dbt
🎧 Random grab-bag of podcast episodes that I've enjoyed recently
🌱 How to use dbt source freshness tests to detect stale data
📅 Upcoming Events
Here are some events happening next month:
Share an event with the community here or view the full calendar
What did you think of today’s newsletter?
Your feedback helps us deliver the best newsletter possible.
If you are reading this and are not subscribed, subscribe here.
Want more Data Engineering? Join our community.
We’ll see you next month!