
Data Engineering Digest, February 2024

Hello Data Engineers,
Welcome back to another edition of the data engineering digest - a monthly newsletter containing updates, inspiration, and insights from the community.
Here are a few things that happened this month in the community:
What are the most complex industries for data engineers?
How Spark is used and deployed in real life.
Are data engineers really just “software engineers”?
Modern code-first BI tools!
Data lake definitions and woes.
Best practices and design patterns for data pipelines.
Community Discussions
Here are the top posts you may have missed:
1. Is there an industry that stands out as highly complex in terms of 'doing data engineering'?
This month, a community member was looking for insights into any particular industries that may be really complex (and thus avoid). And if there are, do any other data engineers know of any tools that can simplify things.
Choosing which industry to work in isn’t always an easy choice so we’re glad this question was asked and can hopefully provide some insight to some of the challenges engineers face. Especially for engineers earlier in their career, the industry that they choose can help define their careers and skill sets.
💡 Key Insight
There are several industries that data engineers believe are more complex for various reasons but there were a few common themes. Several industries seemed more likely to have antiquated data systems, strict security/compliance requirements, large scale data, and then of course messy data.
A few of these industries were:
Manufacturing & Supply Chain/Logistics
Healthcare
Government
Banking/Finance
Looking at these industries, some of them actually aren’t surprising because of the nature of the work. Especially when it comes to working with sensitive data, there are more bureaucratic and security obstacles (as expected).
While these industries may present extra challenges, they often allow engineers to contribute to very impactful work and present innovation opportunities. Data engineers working in these industries often gain industry-specific knowledge that can lead to career growth and stability as well.
2. How is spark really used and deployed in production?
I only have academic knowledge of spark and haven’t used it in a company. I learnt and passed the spark certification, but I don’t have any idea how spark is typically used in companies and how it is deployed.
While doing certifications can be helpful for structured learning this question underscores the importance of bridging the gap between academic learning and practical application. It’s one of the reasons why building personal projects is often recommended for data engineers.
Bookmark these recommended Spark learning resources and project inspiration.
💡 Key Insight
While there were a few mentions of on-prem setups of Spark, the majority of data engineers were using managed services like AWS EMR, Databricks, AWS Glue, Azure Spark pool, and DataProc on GCP. Each of these services have varying levels of configuration from completely serverless like Glue to more configurable services like EMR.
3. Are data engineers really just "software engineers"?
One member shared their recent job application experience for a Senior DE position where despite having significant experience in BI/DE and the company’s tech stack they didn’t pass due to their lack of programming experience in Python.
The recruiter’s exact words were “our data engineers are really software engineers at heart". I'm wondering if this is becoming more and more the case as time goes on.
This question is relevant to data engineers navigating the evolving landscape of demand for certain skills, particularly SWE skills. It highlights the importance of staying updated on industry trends and acquiring diverse skills to remain competitive in the field.
💡 Key Insight
If you look at the history of data engineering and its definition, it is defined as a specialized subset of software engineering that is focused on data which was created out of necessity to deal with large amounts of data.
The community agrees that DE is a subset of Software Engineering and they are expected to manage the data engineering lifecycle and not just BI/Analytics.

As tooling evolves and takes away more of the complexity, a data engineer’s work will continue to move up the value chain (aka the undercurrents).
Part of the reason there may be confusion around data engineering requirements is that it’s not uncommon for folks to transition from business intelligence (BI) to DE and BI typically requires less of the traditional software engineering skills.
You may still see data engineer roles that don’t require SWE skills but now a new role called analytics engineer has become more popular to mark the distinction between software engineering focused DEs and technical business intelligence DEs.
Some folks believe that the industry actually needs more analytics engineers because most companies don’t have enough data to warrant hiring a traditional data engineer.
4. BI Tool Rant
It’s not uncommon for data engineers to be frustrated with the bloat that often emerges when building with traditional BI tools. One member requested suggestions for a code-first BI tool that can be version controlled and have SWE best practices applied to it.
Traditional BI tools were built for analysts and BI developers/engineers, not data engineers. To make their product as sticky as possible (so that the client builds their workflows around the tool and not leave them for a competitor), it is traditionally difficult to migrate off of the platform.
Additionally, the semantic layer is not a new concept but it is traditionally built into the BI tool itself. However, many data engineers are pushing for the semantic layer to be separated so that it is more flexible and can have uses beyond the BI tool, allowing for a true single source of truth.
💡 Key Insight
There are several new tools on the market that are helping to solve this problem. For code-first BI tools the community recommended checking out:
For a semantic layer, folks were recommending cube. It’s worth noting that dbt also has a semantic layer via their MetricFlow integration but you must have dbt Cloud to use it.
5. What the Hell is a Data Lake?
I know it’s a place to store data, but what data structure does it use? Presumably, it is a directory structure and storage is non mutable block storage like S3. Is that it?
Because data lakes are very broad and flexible there are often multiple definitions floating around causing confusion. Data lakes are also less common due to the amount of data and expertise that was historically required to design and run them. Newer platforms are getting better at abstracting away the complexity to the point where you may not even realize you’re using one and it just seems like a regular database.
💡 Key Insight
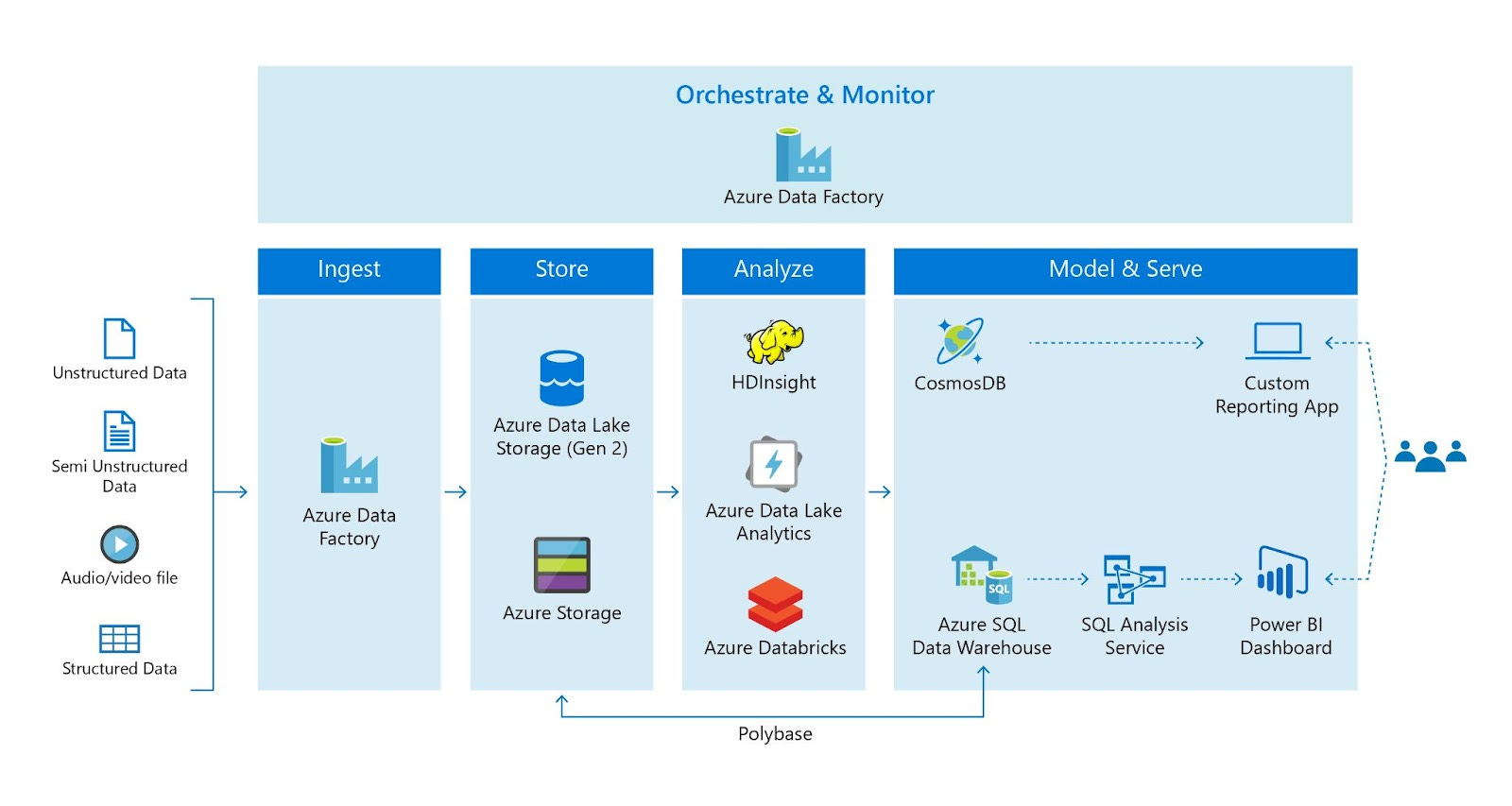
A data lake is a data storage area where multiple sources of data can be stored in their original raw format. They can store large amounts of structured, semi-structured, and unstructured data cheaply. Examples include data stored in file formats like JSON, BSON, CSV and Parquet but also unstructured data like images, audio and video files. Like data warehouses, they typically contain current and historical data used primarily for analytics.
Many data engineers hold the view that data lakes are more difficult to maintain over time and as a result, become a mess of hoarded data that is usually not useful hence the term data swamp. In reality, the same problem can apply to any architecture you choose including data warehouses.
We see customers creating big data graveyards, dumping everything into Hadoop distributed file system (HDFS) and hoping to do something with it down the road. But then they just lose track of what’s there. The main challenge is not creating a data lake, but taking advantage of the opportunities it presents.
- Sean Martin, CTO of Cambridge Semantics
6. Pandas, high coupling and single responsibility principle in data pipelines
The author of this discussion described how they typically end up building monolithic Pandas functions to transform their data despite trying to use best practices like single responsibility principle (SRP). They believed that breaking the functions down didn’t quite make sense since they would be used solely for the main function. They wanted to know if there were any best practices or common design patterns they could use to make their code more readable.
Writing code that works is only the first step and right after that is readability and performance. Luckily, there are many patterns that we can borrow from Software Engineering that solve these problems.
💡 Key Insight
A fantastic resource that was shared was this list of data pipeline design patterns and there is a lot more we can’t cover here so we recommend checking it out. Here were some of the patterns from the list:
Functional design: using functional programming to achieve atomicity, idempotency and no side effects.
Factory pattern: create an abstraction for pipelines that follow a similar pattern.
Strategy pattern: an abstraction to allow for choosing different execution logic (aka different “strategies”) depending on the inputs. Abstraction must have the same input/output parameters.
Singleton, & Object pool patterns:
Singleton: when your program should only have one object of a class for its entire run. For example database connections, logs, etc. Can be difficult to design well and is generally an anti-pattern.
Object pool pattern: builds on the singleton pattern and forms a pool of objects you can use instead. Often used for serving multiple database requests. You may have used this via tools like psycopg2 connection pool.
Overall, it’s okay to break up functions into smaller functions even if they are only going to be called once. What’s more important is how easy it is for a reader to understand what is going on. Another piece of advice was to break the function down into smaller testable steps so that even if it’s not reusable at least it’s testable and easier to maintain.
🎁 Bonus:
👨🚀 Open source orchestration tool 'Houston', an API based alternative to Airflow/Cloud Composer
🎏 What we learned after running Airflow on Kubernetes for 2 years
📅 Upcoming Events
3/8-9: DataTune 2024: A community conference in Nashville, TN! (paid, in-person)
3/14: AWS Innovate: Generative AI + Data Edition (free, virtual)
Share an event with the community here or view the full calendar
Opportunities to get involved:
Share your story on how you got started in DE
Want to get involved in the community? Sign up here.
What did you think of today’s newsletter?
Your feedback helps us deliver the best newsletter possible.
If you are reading this and are not subscribed, subscribe here.
Want more Data Engineering? Join our community.
Want to contribute? Learn how you can get involved.
Stay tuned next month for more updates, and thanks for being a part of the Data Engineering community.