
Data Engineering Digest, February 2026

Hello Data Engineers,
Welcome back to another edition of the data engineering digest - a monthly newsletter containing updates, inspiration, and insights from the community.
Here are a few things that happened this month in the community:
Schema drift: whose problem is it?
Too many data tools?
Is your analytics stack running in prod?
Pinterest’s CDC overhaul
Netflix’s no-downtime database migration
dbt’s AI agent skills
Community Discussions
Here are the top posts you may have missed:
1. How do you handle ingestion schema evolution?
“I was under the impression we all use schema evolution with alerts now since it’s widely available in most tools but it seems not?”
One data engineer was surprised to learn that schema changes from upstream systems remain a top cause of pipeline maintenance and failures. They opened the floor to the community: how are you actually handling schema evolution in 2026?
Schema drift is when tables, columns, and data types are added, removed, or changed and not synced to downstream consumers. These inconsistencies can cause data to be misinterpreted, lost, and often require manual data pipeline fixes. As organizations ingest from more external sources - APIs, SaaS platforms, partner feeds - the “move fast and break things” culture of upstream systems collides with the stability requirements of analytics.
💡 Key Insight
The responses revealed a spectrum of approaches - from teams with no solution at all (“it routinely breaks our core pipelines”) to more sophisticated setups with data contracts and schema registries. The debate centers on whether to embrace automatic schema evolution or treat schemas as strict contracts.
The community is split into three camps:
The Contract Purists: “Schema evolution is just a dirty band-aid,” argues one veteran. Data contracts and domain objects should validate data at ingestion - required columns, types, formats, and values. If it doesn’t match, it fails.
The Pragmatists: Store everything raw first (as JSON blobs or raw files), then normalize downstream. “Your upstream doesn’t care about you, so better leave them alone.” This approach prioritizes availability over strict validation.
The Relationship Builders: Proactively doing things like coffee chats with data owners can help build trust and improve two-way communication.
The ideal approach combines elements of all three: version schemas explicitly, validate against declared versions, route invalid payloads to a holding area (e.g. dead-letter queue) for review, and maintain both raw and normalized storage so schema evolution never requires rewrites. Relationship building will help with getting buy-in from upstream data stewards to help maintain data contracts.
2. Can someone explain to me why there are so many tools on the market that don’t need to exist?

“15 years ago, things were simple. You grabbed data via C#, loaded into SQL Server, manipulated the data and you were done. Why are there so many f’ing tools on the market that just complicate things?”
A self-described “old school data guy” with 15 years of experience posted a frustrated rant about the explosion of tools in the modern data stack: Fivetran, dbt, Airflow, Prefect, Dagster, Airbyte... “do people not know how to write basic SQL?”
Tool fatigue is real. Every data platform has its own proprietary terminology, abstractions, and incentives - adding cognitive overhead to what is fundamentally a three-step process: get data, make it useful, provide useful data.
💡 Key Insight
It’s not that new: 15 years ago there were dozens of options as well. Today there are still dozens of tools and maybe more due in part to a VC funding boom in the last decade. Over the past year or so that trend is reversing and we’ve been covering the market consolidation.
Scale matters: Today there are larger data volumes, more data sources, more complex data requirements, etc. This is where tools like Airflow solve a pain point over cron.
Best practices: Data engineering takes software engineering principles and best practices and applies them to data. The tools that exist today are made for these workflows. As an example, dbt largely is “just SQL” but version controlled with dependency understanding and documentation, testing, contracts, etc.
The consensus? Know the open-source foundations (especially Apache projects) to understand what each tool category does. Then choose deliberately based on your actual scale and team size, not what the market is hyping.
3. Dev, test and prod in data engineering. How common and when to use?
A data engineer realized they had no idea how to provide a table to a colleague who needed it in a test environment - because their entire analytics stack runs directly in production. They asked the community: how common is this, really?
The gap between software engineering practices and data engineering reality is often wider than we admit. While software teams wouldn’t dream of shipping untested code, many data teams operate daily in production with no safety net.
💡 Key Insight
We should always be using dev, test and prod environments - even for analytics. Modern tools and cloud databases make this much easier than you might think. For example, many databases now have straightforward db/schema/table replication functionality that allows you to easily spin up a new environment. Versioned code tooling like dbt allows you to then use dynamic connections to target and build in different environments. You can also filter or generate data as needed depending on your use case.
Multiple community members shared stories of analytics teams running everything in prod for years - until something breaks spectacularly. “What finally forced the change was someone running a bad join that broke a dashboard right before an exec review.” Nobody wants to be the person who has to explain why code that could be properly tested wasn’t.
Industry Pulse
Here are some industry topics and trends from this month:
1. Next Generation DB Ingestion at Pinterest

Pinterest replaced a patchwork of batch ingestion pipelines - some with 24+ hour data delays - with a unified Change Data Capture (CDC) framework built on Kafka, Flink, Spark, and Iceberg. Instead of reprocessing entire tables daily, the new system captures only what changed and lands it in their data lake within 15 minutes to an hour. The article is worth reading for the concrete Iceberg optimization details: their bucket join workaround alone cut compute costs by 40%+ on large table merges. Part 2 on automated schema evolution is coming next, which is arguably the harder problem in any CDC-based architecture.
2. Automating RDS Postgres to Aurora Postgres Migration
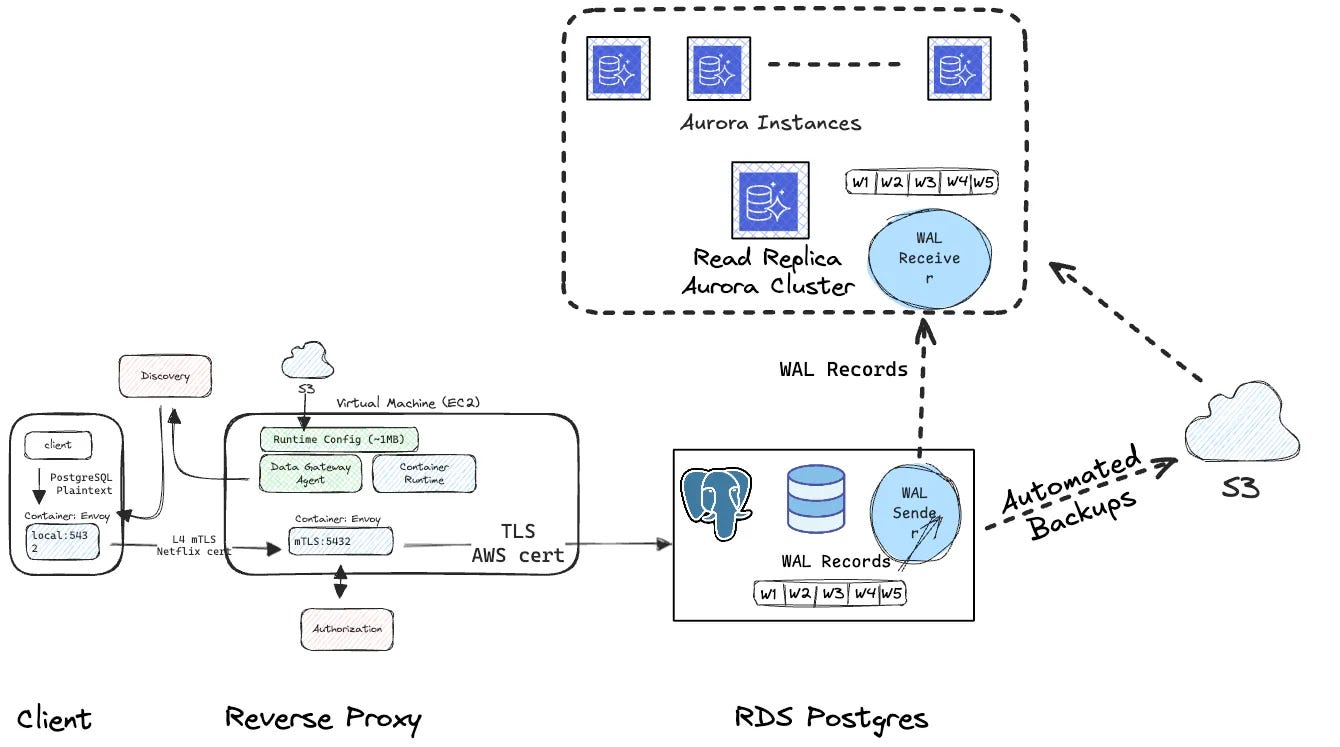
Netflix built an automated self-service tool to migrate all ~400 of their PostgreSQL clusters to Amazon Aurora PostgreSQL - no database passwords required, no application code changes. The key was a traffic router sitting between apps and databases, so switching databases is just a config update, like changing a forwarding address. Average downtime was around 10 minutes, and the article covers some real gotchas worth knowing, like stale replication slots silently inflating your lag metrics.
3. Make your AI better at data work with dbt’s agent skills
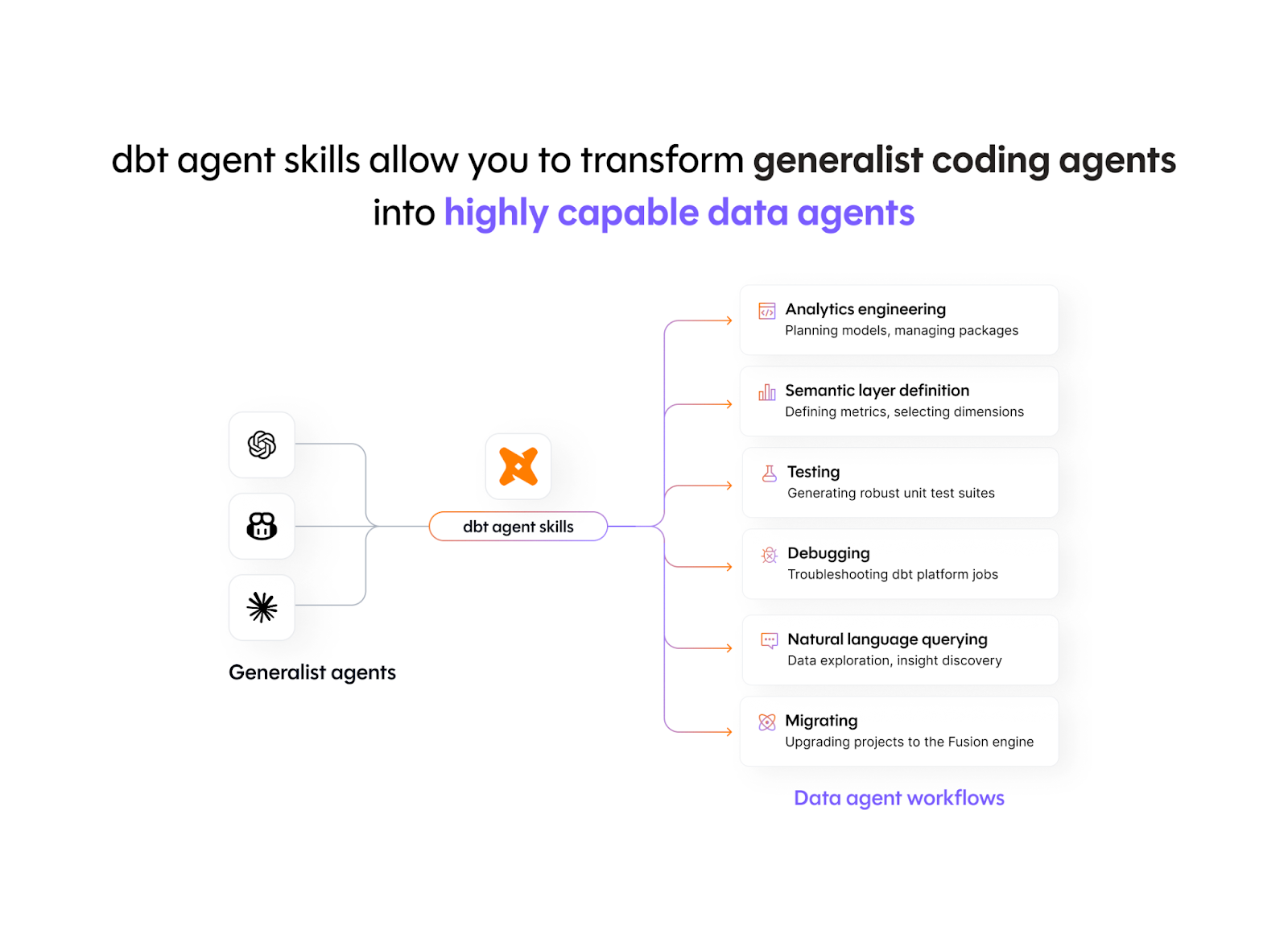
dbt Labs released an open-source collection of agent skills designed to turn generalist coding agents (Claude Code, Cursor, Codex, etc.) into dbt-aware data agents - embedding years of community best practices directly into how AI tools interact with your project. The skills cover analytics engineering workflows, semantic layer setup, job debugging, and Core-to-Fusion migrations, and install in a single command. In benchmarking, the biggest gains showed up in iterative DAG work, which is exactly where AI agents tend to fall apart in practice.
🎁 Bonus:
📊 2026 State of Data Engineering Report - 1000+ responses from data engineers
🙉 How MinIO went from open source darling to cautionary tale
📥 I built a website to centralize articles, events and podcasts about data
📅 Upcoming Events
3/25: Metabase JOIN
Share an event with the community here or view the full calendar
Opportunities to get involved:
What did you think of today’s newsletter?
Your feedback helps us deliver the best newsletter possible.
If you are reading this and are not subscribed, subscribe here.
Want more Data Engineering? Join our community.
Stay tuned next month for more updates, and thanks for being a part of the Data Engineering community.