
Data Engineering Digest, May 2026

Hello Data Engineers,
Welcome back to another edition of the data engineering digest - a monthly newsletter containing updates, inspiration, and insights from the community.
Here are a few things that happened this month in the community:
Where should the knowledge from your AI agents live?
CI/CD tips: what’s worth catching, and what isn’t
Should you let an LLM query your tables?
The Iceberg catalog wars heat up
DuckDB finally gets a client-server protocol
Cloudflare’s plain-English query agent, Skipper
Community Discussions
Here are the top posts you may have missed:
1. How are you centralizing knowledge from AI agents like Claude Code?
A team leaning hard on Claude Code hit a wall. Every time the agent worked out a tricky fix or made a design decision, it wrote notes into a markdown folder inside that one repo. Useful context ended up trapped where nobody on another project could find it. They asked the community how to build a shared knowledge base without over-building it.
As more teams hand work to coding agents, the notes those agents leave behind pile up fast. Storing them is the easy part. The hard part is finding the right note later, and trusting it once you do.
💡 Key Insight
The discussion converged on a few patterns:
The top reply built a single “ai-docs” repo that holds shared rules plus per-project notes, then links only the relevant pieces into the agent’s workspace (using symlinks, so there’s one source of truth) when a session starts. The agent gets what it needs up front instead of feeling around for it.
Tier your notes by trust. One member sorts them into three buckets: human-reviewed (architecture decisions, post-mortems), agent notes that survived a second review pass, and raw agent output flagged as unvetted. Raw, unchecked output left in the pile just poisons future context.
A small, structured catalog beats fuzzy search. For “did anyone decide this on another project?”, a tidy index of topic plus project plus decision status finds the answer faster than vector similarity.
A few folks pointed to lighter options too: a team monorepo, a shared Obsidian vault, or Databricks’ open-source AI dev kit for baked-in best practices. Across all of it, one theme held: the storage tech matters less than the write discipline. Pick any backing store and spend your effort deciding which notes earn a spot in the trusted pile.
2. CI/CD tips for a data stack
A data engineer on GitHub and Microsoft Fabric (notebooks, lakehouse, semantic models, reports, and pipelines) wanted to add continuous integration and delivery, the practice of automatically checking and shipping code on every change. Beyond the obvious environment deployments, what checks and tests are actually worth adding?
Data teams often bolt CI/CD on late, after something breaks in production. Adding quality gates early saves real pain later. The catch is that it’s just as easy to over-build them.
💡 Key Insight
The practical picks that got the most agreement:
Start with smoke tests (does the code even run and parse?) before chasing full unit-test coverage. Unit testing pipeline code is often more trouble than it’s worth.
For linting and formatting, the crowd favorites were Ruff for Python, SQLFluff for SQL (though several find SQL linting tedious), Hadolint for Docker files, and actionlint or zizmor for GitHub Actions.
Type hints split the room. Most agreed they help, but pointed out that adding hints is not the same as running a type checker like mypy or pyright. Full static checking is worth it for shared libraries and APIs, and overkill for one-off pipeline code.
Package your reusable Python separately from the business logic in notebooks so you can actually test it.
SQLMesh fans noted it plans your whole pipeline and runs audits and tests only on the models that changed, which is about as close to real CI/CD as data work gets.
Rule of thumb: gate the basics first (lint, smoke test, deployment checks), then add new gates as real production incidents teach you what to catch. Don’t try to catch everything.
3. Should you let an LLM query your tables?
“I’ve had a ton of people in my company come to me asking about giving LLM’s access to our databricks tables. I’m a little sussed out by passing data to an LLM (we do have the enterprise plans, which ik means they don’t train on that data) but I wanted to know others within the same professions thoughts on it.”
This question lands on a lot of desks right now. Business users want to ask questions in plain English, and if the data team says no, they often find a way around it. So the real challenge is how to say yes safely.
💡 Key Insight
Don’t accidentally build a way around your own access controls. If marketing can’t see salary data in the dashboard, they shouldn’t be able to ask a bot what Joe earns.
Secondly, never point the model at raw tables - expose a curated reporting layer of views, ideally behind a semantic layer (a map that tells the model what “revenue” or “active user” actually means). Keep the model out of the data path: a common setup has the model write SQL, a separate tool runs it, and only small results come back, with Snowflake and Databricks (through Cortex and Genie) keeping this inside one trust boundary so the data never leaves. Then add guardrails - read-only access, query budgets to control cost, and full auditing of what was asked.
Industry Pulse
Here are some industry topics and trends from this month:
1. The Iceberg catalog wars heat up

Apache Iceberg is an open table format, a way to store huge tables as plain files while keeping database-like features. A wave of May releases pulled the spotlight onto the catalog, the service that tracks where each table’s data and metadata live.
Iceberg 1.11.0 (May 27) was a major release. The REST catalog can now plan scans on the server, which moves heavy metadata work off the query engine and speeds up planning at scale. A finalized File Format API lays the groundwork for new formats like Lance and Vortex. The release also adds built-in table encryption (with Google KMS support), makes Spark 4.1 and Flink 2.1 the default build targets, drops Spark 3.4 and Java 11, and marks the V3 features (deletion vectors, the Variant type, geospatial types, and nanosecond timestamps) as stable.
Snowflake made Iceberg v3 generally available on May 7, bringing row lineage and deletion vectors (merge-on-read by default). This month it also made external write support generally available through its Horizon catalog, so an outside engine like Spark can read and write Snowflake-managed tables through a single endpoint.
Databricks answered on May 28 with “Advancing Apache Iceberg on Databricks,” moving Managed Iceberg, Iceberg v3, and Foreign Iceberg into general availability in Unity Catalog. It also said Iceberg v4 and Delta 5.0 will converge on one shared metadata structure.
Continue reading:
2. DuckDB finally gets a client-server protocol
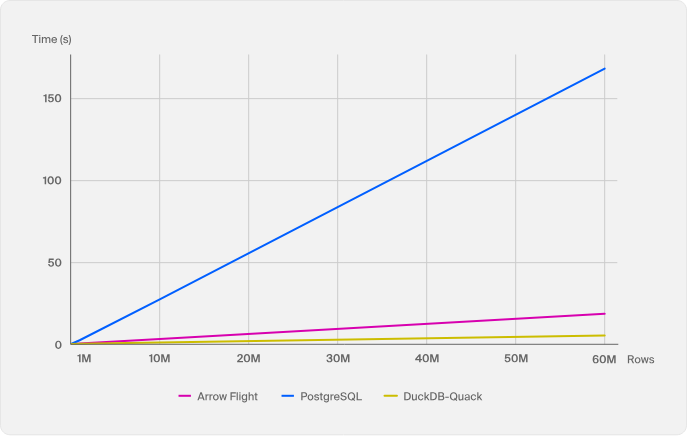
DuckDB is a fast database that runs inside a single process, which makes it great on one machine and awkward to share. Its biggest gap was that it couldn’t easily act as a shared server many clients write to at once. The new “Quack” protocol, shipped as an extension, closes that gap. It lets DuckDB run as a multi-writer client-server database over HTTP, works through load balancers, and even runs in the browser through DuckDB-Wasm (WebAssembly). DuckDB’s own benchmark claims it moved 60 million rows in under 5 seconds, faster than Arrow Flight SQL (a common protocol for moving large query results between systems). A production-ready version is planned for DuckDB 2.0 this fall, which would move DuckDB from a single-machine tool toward something a whole team can share without standing up a separate database server.
3. Cloudflare’s plain-English query agent, Skipper
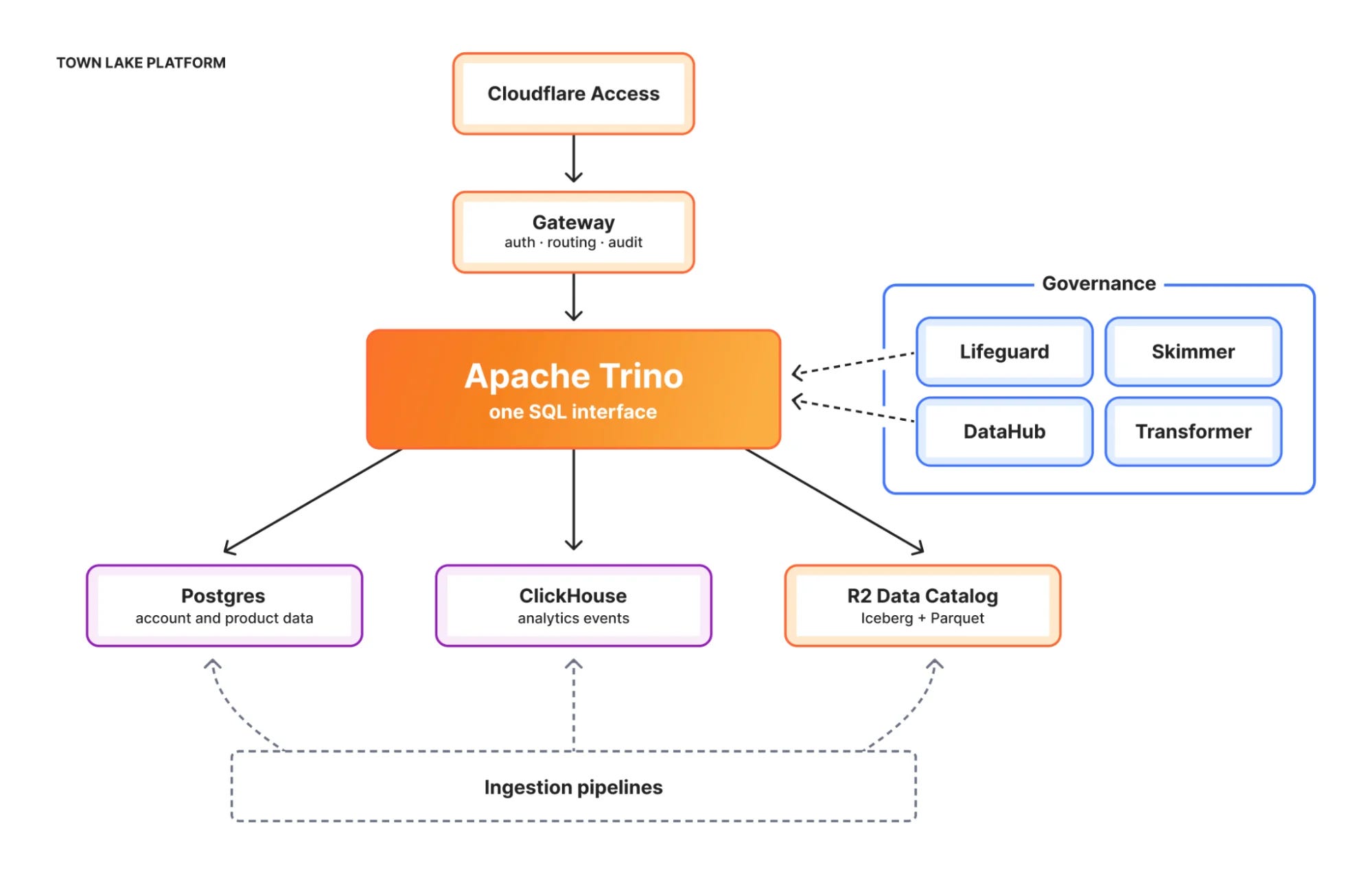
Cloudflare detailed how it built Town Lake, a single lakehouse on Apache Trino and Iceberg sitting on its R2 storage, plus Skipper, an agent that turns plain-English questions into SQL you can audit. The real work went into the boring plumbing: per-row access control, tables locked by default until an automated checker (nicknamed “Skimmer”) scans them for personal data, query auditing, and short-lived credentials. Billing questions alone made up 53% of queries (91,760 of them from 324 employees), and the network behind all this handles more than a billion events per second.
🎁 Bonus:
📐 Data Modeling for Analytics Engineers: The Complete Primer (Nikola Ilic)
🔦 Don’t Go Dark: Visibility Is a Data Engineering Skill (Chris Hillman)
📅 Upcoming Events
6/1-6/4: Snowflake Summit 26
6/15-6/18: Databricks Data + AI Summit 2026
Share an event with the community here or view the full calendar
Opportunities to get involved:
What did you think of today’s newsletter?
Your feedback helps us deliver the best newsletter possible.
If you are reading this and are not subscribed, subscribe here.
Want more Data Engineering? Join our community.
Stay tuned next month for more updates, and thanks for being a part of the Data Engineering community.