
Data Engineering Digest, November 2023

Hello Data Engineers,
Welcome back to another edition of the data engineering digest - a monthly newsletter containing updates, inspiration, and insights from the community.
📢 Community Announcements 📢
Tomorrow is our quarterly salary discussion where data engineers from all over the world transparently share their compensation and experiences. It’s one of our community’s most popular events and you can join the discussion tomorrow here.
Here are a few things that happened this month in the community:
Comparing streaming OLAP databases
How to choose where to run your Python job
Lakehouse architecture basics and examples
Snowflake streams/tasks vs dbt incremental models
Things DEs should avoid spending time learning
The Data Engineering Case for Developing in Prod
Community Discussions
Here are the top posts you may have missed:
1. Thoughts on OLAPs Clickhouse vs Apache Druid vs Starrocks in 2023/2024
A data engineer recently reached out to the community asking for insights into some popular OLAP databases tailored to their specific needs. The three mentioned fall into a particular category of OLAP databases which we typically call real-time or streaming analytics databases. Other notable managed service options in this category are Rockset and Materialize.
These types of databases are typically used for real-time analytics (millisecond scale) as well as serving a high number of concurrent queries for things like fraud detection, real-time personalization, and customer-facing dashboards.
💡 Key Insight
Here are some of the pros and cons of each tool from the discussion:
Note that these are just a few high-level points and it is not meant to be a comprehensive comparison of these tools.
Apache Druid
Pros:
Well known for its real-time data storage and indexing (been around for over a decade)
Extremely performant
Can support massive PB-level scale
Cons:
Deployment is more complex compared to the other options
Community and resources don’t feel as active/maintained as other options
Doesn’t yet support complex joins and window functions
Starrocks
Pros:
Supports complex queries at real-time latencies
Easy to deploy and use
Support for querying data lakehouse formats (more on this topic below)
Cons:
Multiple people mentioned lacking documentation
Doesn’t feel “production ready” to some folks
Clickhouse
Pros:
Consistently came up as a solid choice
Simpler architecture compared to Druid and easy to deploy
Cons:
Worse join performance relative to other options
Doesn’t support partial updates
There’s a lot more technical discussion going on in this post than we could cover. You can join the conversation here.
2. Running Python Jobs in cloud
Looking for the best way to run your Python API scripts on AWS? One of our members had the same question. They mentioned that the data is small so they don’t need a distributed processing engine like Spark but complained about the time limitation of AWS Lambda Functions (15 min limit).
There are several compute options on all of the major cloud providers and many of them look alike because they're built on similar foundations. So how do you decide which service to use?
💡 Key Insight
There’s not enough information to answer this member’s specific question but we can dive into the different options on AWS specifically for running Python data pipelines.
Lambda - Ideal for small jobs (time limit of 15 mins) and is the simplest to use so use it if you can.
Batch - Ideal for longer running jobs (15+ mins). AWS Batch can use Fargate, EC2, or EKS (Fargate usually recommended) under the hood and it terminates jobs automatically when done.
Fargate - Fargate is a serverless version of EC2 and it’s typically used for running applications/services. We only recommend using Fargate for DE if you need a server running 24/7 otherwise you should use Batch.
EC2 - A server where you have the most flexibility to configure and control the details. Again, the options above are typically better for data pipelines because they are serverless and don’t require maintenance but DEs do still use EC2 outside of data pipelines. DEs may use EC2 instances to perform database migrations, restores, and other short-term use cases.
3. Lakehouse Architectures - How does it look like for you?
“Hi All -- Curious to understand what industry, tech stack, business use case and any other information you can provide on how your lakehouse is set up.
I haven't moved away from using a DWH…so the idea of doing ETL in a Lakehouse and setting it up seems foreign to me.”
The data architecture landscape is constantly evolving and data engineers are always trying to understand the latest breakthroughs that they can take advantage of. Staying updated on how other data engineers are leveraging data lakehouses can give us insights into best practices, potential challenges, and the benefits of this emerging architecture trend.
💡 Key Insight
A data lakehouse is a data architecture pattern that creates a single platform which combines the key benefits of data lakes (ability to store raw unstructured data in low-cost storage) and data warehouses (query performance and management of structured data).
The data lakehouse has been popularized with the advent of open table data formats like Apache Iceberg and Delta Lake. These open-source storage frameworks enable the flexibility of a data lake with the benefits of a data warehouse like ACID transactions, audit history, DML operations, schema evolution, and time travel.
These formats enable this functionality via additional metadata that is stored alongside the data. For example, the Delta Lake format saves transaction log metadata alongside the data in JSON files.


Similarly, Iceberg also stores metadata in JSON files in a separate layer from the data itself.
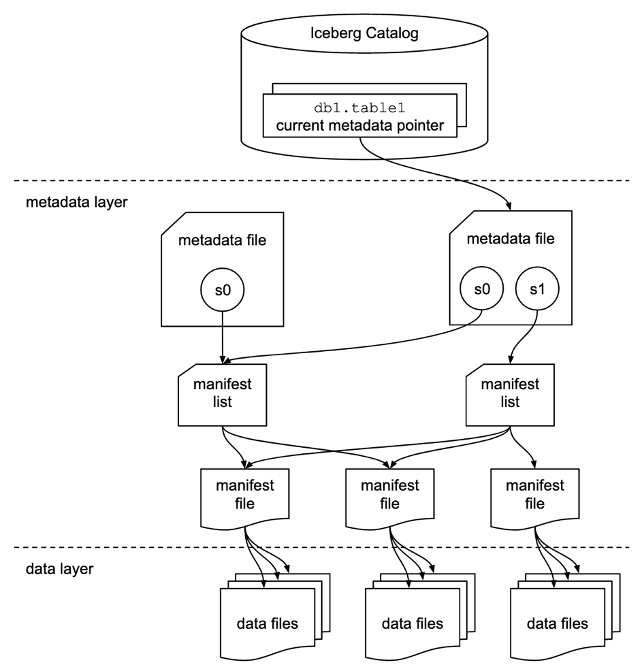
We didn’t see a lot of members using or sharing their lakehouse setup but below are a few examples from the discussion
AWS Glue (Serverless Spark) -> Apache Hudi Tables in S3, AWS Data Catalog, AWS Athena to query
Databricks (managed lakehouse)
(Recommended Video): Toyota Motor NA: Lake House Architecture for Data and Analytics
(Recommended Video): Apache Hudi vs Delta Lake vs Apache Iceberg - Lakehouse Feature Comparison
4. Snowflake Ingestion using Tasks and Streams VS Airflow and DBT Incremental Models
This discussion was between the choice of using dbt incremental models or Snowflake tasks and streams for ingesting data. The data engineer making the choice is mostly interested in maintainability and being able to recover from issues.
This is a common decision for data engineers setting up a new Snowflake warehouse or migrating to one. Both tools can do the job but there are tradeoffs between each.
💡 Key Insight
Snowflake streams and tasks by themselves don’t have great visibility. For example, you must explicitly set up notifications on tasks if you want to be notified when they fail. It’s improving but as of right now folks still recommend using a workflow orchestrator to run workloads on Snowflake for the observability. With dbt, you are already using a workflow orchestrator so if it fails it’s easier to understand and debug. Most agree that it’s also easier to use than streams and tasks.
In terms of performance, Snowflake streams/tasks are better suited for near real-time data ingestion and transformation whereas incremental models are better suited for traditional batch jobs.
5. Things you learned that were of no use.
It can be frustrating to feel like you’ve wasted a ton of time learning something new only to realize that it won’t be useful or transferable to other tools. If you’ve ever felt like this, you’re not alone.
Our community members opened up about their experiences with various tools and languages they felt turned out to have little to no value in their careers. It’s sometimes unavoidable that you will have to learn how to use or maintain a tool/language that won’t be helpful later on but remember to focus on the data engineering concepts over the specifics of the tool.
💡 Key Insight
The main themes that emerged from this discussion revolved around no-code tools and proprietary programming languages (unsurprisingly). Some of the most upvoted comments included:
Oracle Cloud Data Warehouse and certifications
Talend (a low-code platform)
Enterprise services from IBM and Microsoft
MDX (Multidimensional Expressions) for SQL Server Analysis Services
6. The Data Engineering Case for Developing in Prod
The article being discussed offers a refreshing and somewhat controversial perspective on data engineering best practices. The title certainly grabs your attention, but it might be misconstrued as advocating for the elimination of separate environments for code, which isn't the case.
The key arguments were solid and well presented and it sparked a valuable discussion in the community which we wanted to share.
💡 Key Insight
While the title feels a bit provocative, the author’s argument is solid and well presented. They essentially argue for developing with production data while maintaining separate environments for code inside an account.
Here are some of the highlights from the article and the community discussion:
It takes a lot of effort to maintain fake datasets for data engineering pipeline testing. Even if the fake data looks okay, you have to re-implement business rules otherwise you won’t catch most edge cases.
It’s not easy to recreate the volume and variety you would see without production data. You can use a smaller portion of production data but then you won’t know how many resources to provision for your data pipeline once it goes into production.
Data engineering tooling has improved making it simpler and safer to work with production data by allowing DEs to clone datasets and isolate resources so you can run production and development workloads without impacting each other’s performance.
Most Data teams are already constrained in resources which is why most develop in a production account in the first place.
🎁 Bonus:
📅 Upcoming Events
12/13: Trino Summit 2023 (Virtual)
Share an event with the community here or view the full calendar
Opportunities to get involved:
Share your story on how you got started in DE
Want to get involved in the community? Sign up here.
What did you think of today’s newsletter?
Your feedback helps us deliver the best newsletter possible.
If you are reading this and are not subscribed, subscribe here.
Want more Data Engineering? Join our community.
Want to contribute? Learn how you can get involved.
Stay tuned next month for more updates, and thanks for being a part of the Data Engineering community.