


Data Engineering Digest, November 2024

Hello Data Engineers,
Welcome back to another edition of the data engineering digest - a monthly newsletter containing updates, inspiration, and insights from the community.
Here are a few things that happened this month in the community:
Ideas on the self-serve BI myth
Data Vault 2.0 challenges
The semantic layer and its resurgence explained
Design patterns that allow LinkedIn to scale
A recap on change data capture from Pinterest
AirBnB’s lambda architecture for identifying user signals
Community Discussions
Here are the top posts you may have missed:
1. Is there truly a usable self-serve BI tool?
Every tool I’ve seen demands a mountain of engineering just to get started. What’s your take on the so-called "self-serve" BI solutions out there?

Self-serve business intelligence (BI) is a term used to describe the ability for non-technical business users to answer their own questions about the business and explore data and create visualizations independently of a data team.
In theory, it would reduce the analytics burden on data engineers and analysts but the self-serve BI “myth” has become a joke as it is notoriously difficult to implement successfully.
💡 Key Insight
Each tool has its tradeoffs and some may be better than others but self-serve is largely not a tooling problem. A self-serve model typically requires a large investment in proper data modeling, documentation, training and data quality testing to be successful.
Here are some tips from the DE community:
Rely on your analytics team, not business users, to curate your data layer. No tool can fix bad data.
Identify power users in your organization and give them the proper resources, training, and permissions. They will help you amplify your impact and educate other users in the organization.
Invest in documentation and make data easy to use (business friendly column names, few to no joins).
Allow easy exports to Excel. Excel isn’t going away anytime soon.
2. Data vault 2.0
Our new architect is not a fan of our current setup of medallion, and highly recommends going for data vault instead.
Unlike data vault (DV) 2.0, a medallion architecture is not a data modeling technique, it’s simply one method for organizing your data into defined steps in the ETL process. You can use medallion with any data modeling technique or you can skip it altogether.
💡 Key Insight
You typically don’t see large architectural changes unless there are growing pains with the current architecture or the technical debt becomes too large. Of course, we don’t have all of the context here but it’s unclear why these two things are being compared. Because it’s unclear, the best advice here is for the person suggesting the change to put together a cost benefit analysis and create a proof of concept to try and get buy-in from the team. Data initiatives like this where one person tries to implement something without buy-in from the rest of the team almost always fail.
Data vault 2.0 is considered a more advanced data modeling technique and requires an upfront investment in time and training but makes it easy to add new data sources and it automatically tracks historical changes by default which is great for auditing. The overall community sentiment is clear that data vault has a lot of promise in theory but the additional complexity often doesn’t deliver on the promised value. If your team isn’t already familiar with DV then it may not be worth the investment necessary.
3. Please help me blow through the smoke: what is a semantic layer?

💡 Key Insight
A semantic layer is a virtual layer that sits on top of the data warehouse and provides a simplified business-friendly view of the underlying data. It acts as an abstraction that allows users to interact with the data using natural language queries or specific business terms, rather than having to understand the technical details of the database schema.
Semantic layers have been around for decades but they are trending again. They have historically been solely part of a BI tool offering but more recently there have been standalone options gaining popularity because they allow you to avoid vendor lock-in. In the past year or so it’s trending again due to the rise of AI which relies on a semantic layer to deliver better results.
Industry Pulse
Here are some industry topics and trends from this month:
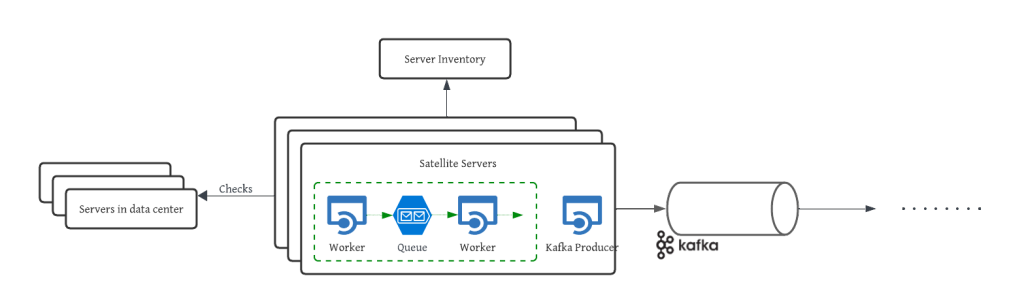
1. Navigating the scale: how design patterns power LinkedIn’s infrastructure
LinkedIn goes back to the basics and shares how they apply common design patterns when designing real-life architectures that can scale. This article mainly focuses on how Linkedin manages their massive fleet of servers using the producer-consumer which is one of the most popular patterns used in data engineering today.
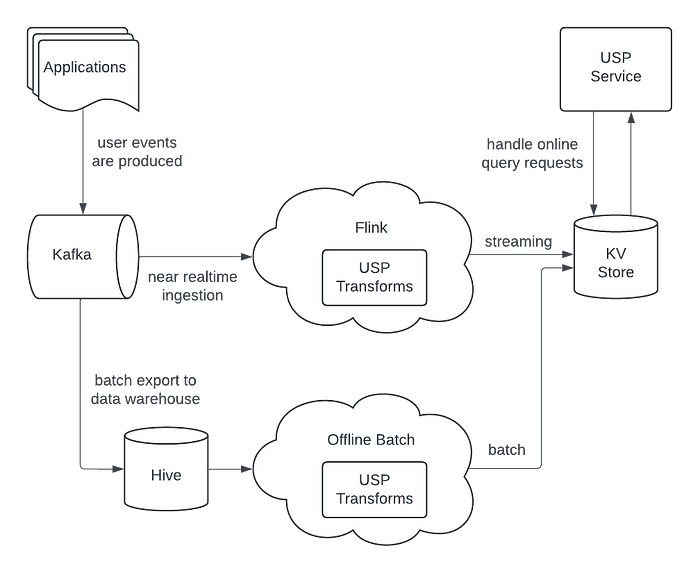
2. Change Data Capture at Pinterest
Change data capture is a crucial technology used in data engineering that enables a wide variety of use cases. This month, Pinterest shared their journey of implementing CDC for all of their databases and why it’s so important.

3. Building a User Signals Platform at Airbnb
Understanding user actions is critical for delivering a more personalized product experience. This blog post explores how Airbnb developed a large-scale, near real-time stream processing platform for capturing and understanding user actions, which enables multiple teams to easily leverage real-time user activities. Additionally, it discusses the challenges encountered and valuable insights gained from operating a large-scale stream processing platform.
🎁 Bonus:
📈 How Canva monitors 90 million queries per month on Snowflake
🔝 Top Skills for Data Engineers - Data from 100 Fortune 500 Job Descriptions
📅 Upcoming Events
12/11-12: Trino Summit 2024
Share an event with the community here or view the full calendar
Opportunities to get involved:
Share your story on how you got started in DE
Want to get involved in the community? Sign up here.
What did you think of today’s newsletter?
Your feedback helps us deliver the best newsletter possible.
If you are reading this and are not subscribed, subscribe here.
Want more Data Engineering? Join our community.
Want to contribute? Learn how you can get involved.
Stay tuned next month for more updates, and thanks for being a part of the Data Engineering community.