


Data Engineering Digest, October 2024

Hello Data Engineers,
Welcome back to another edition of the data engineering digest - a monthly newsletter containing updates, inspiration, and insights from the community.
Here are a few things that happened this month in the community:
Should you skip the warehouse and go straight to lakehouse?
What ever happened to the modern data stack?
Data engineering trends to watch for in 2025.
Cloudflare dives deep into how their new Vector DB works.
Microsoft shares how to do complex data extraction for documents on Azure.
Pinterest adopts a new K8’s powered workflow orchestrator (Apache YuniKorn).
Community Discussions
Here are the top posts you may have missed:
1. Is there a trend to skip the warehouse and build on lakehouse/data lake instead?
Curious where you see the traditional warehouse in a modern platform. Is it a thing of the past or does it still have a place? Can lakehouse/data lake fill its role?
Let’s start with some context with a brief high-level overview of each of these data storage architectures.
Data Warehouse: Optimized for historical analytics on structured and semi-structured data. Typically comes with all of the tools needed for data governance.
Data Lake: Optimized for storing massive amounts of raw data and can store data of any format (structured, semi-structured, unstructured). Cheaper storage and compute vs data warehouse but more time and expertise required to manage. Typically less performant than data warehouses for historical analytics on structured and semi-structured data.
Data Lakehouse: A data lake except structured and semi-structured data is stored in an open table format which adds metadata that can be used to unlock features and performance typically available in data warehouses.
While it’s unclear how common it is, some organizations decide to have a combination of multiple architectures like our member is suggesting in order to gain additional functionality or save money. For most companies, the added complexity of a combined architecture is unlikely to be worth the benefit so what the question really boils down to is can a data lakehouse replace a data warehouse all together?
💡 Key Insight
While data lakehouses have only become popularized in the last few years, they are quickly gaining momentum and seeing a large influx of investment.
Read our last edition if you missed our breakdown of the open table format war which is a key technology that unlocks the data lakehouse.
The community seems to be split - while in theory data lake houses can cover most use cases a data warehouse can, it's still a bit premature to say. There is still plenty of stitching together disparate tools and missing integrations. Data warehouses may still have an advantage for a while due to more mature features and integrations with BI/ETL tools.
One possibility in the future is that the complexity of managing a data lakehouse may just be abstracted away and come in what looks like a traditional data warehouse's clothing. AKA your data is stored in your environment but you don’t need to stitch together several services to manage it.
What do you think the future of the lakehouse looks like?
2. What happened to modern data stack?
There was a lot of buzz around Modern Data Stack a few years ago. Basically, a combination of data dump tool + transformations + "reverse" ETL around a warehouse… Does anyone use this stack significantly, or is there any other preferred set of tools for non-ML data engineering?
💡 Key Insight

The modern data stack was primarily a marketing term but many of the tools mentioned are still being used today. That being said, a few fundamentals have changed. Part of this is due to AI now being the topic of discussion, crowding out MDS and other trends. Another factor is that the zero interest-rate policy (ZIRP) is over, causing companies to scrutinize spending and while the MDS did make many things easier it also made it easier to part with your money.
The MDS made it much easier to work with data, and it also made it much easier to do dumb things more quickly.
- Joe Reis, Everything Ends - My Journey With the Modern Data Stack
Related reading: Is the "Modern Data Stack" Still a Useful Idea? And A Brief History of Modern Data Stack
3. 2025 DE trends
As 2024 comes to a close, some folks are already looking forward towards potential trends for the next year.
If you had to guess, what tools, methodologies, concepts, languages, etc. do you think will grow in the next year?
Data engineering is constantly evolving and it’s important to keep a pulse on the trends that may shape the future. Additionally, with the current instability in the tech job market, data engineers may be trying to stay up to date with the latest innovations to remain competitive.
💡 Key Insight
Here’s a few of the top trends the community believes are likely to see significant growth in the coming year:
Data Lakehouse: Data engineers are looking forward to increased features and performance gained from open table format innovation while vendors are expected to compete on the data catalog side.
Data Mesh: This organizational pattern is still expected to be a trend primarily in large organizations with a large data team. Will it make organizations more agile or will it result in business as usual?
Rust-based tooling: Libraries like Polars and datafusion are extremely popular due to their huge performance benefits, much of which is attributed to them being built in rust.
Innovation in workflow orchestrators and data ingestion tools: Expect better tooling and easier access to 3rd party data sources.
Data Security: Security breaches are still commonplace and costly. More organizations than ever are requiring vendors to have security accreditations in order to do business (forcing them to improve security). Software that helps identify and remediate security issues is also becoming more commonplace.
Data quality & semantic layers (driven by AI): Huge investments have been made in AI and companies are realizing that data quality (unsurprisingly) and semantic layers are necessary in order to take full advantage of their investment. Several companies are now building their own semantic layers to capture this trend.
What do you think will be an important trend for DE in 2025?
Industry Pulse
Here are some industry topics and trends from this month:
1. Building Vectorize, a distributed vector database, on Cloudflare’s Developer Platform
This month Cloudflare released a dive deep into how they built a Vector DB service on their developer platform. It’s a fantastic post into how vector databases work, why they are important, and how Cloudflare built and optimized their version.

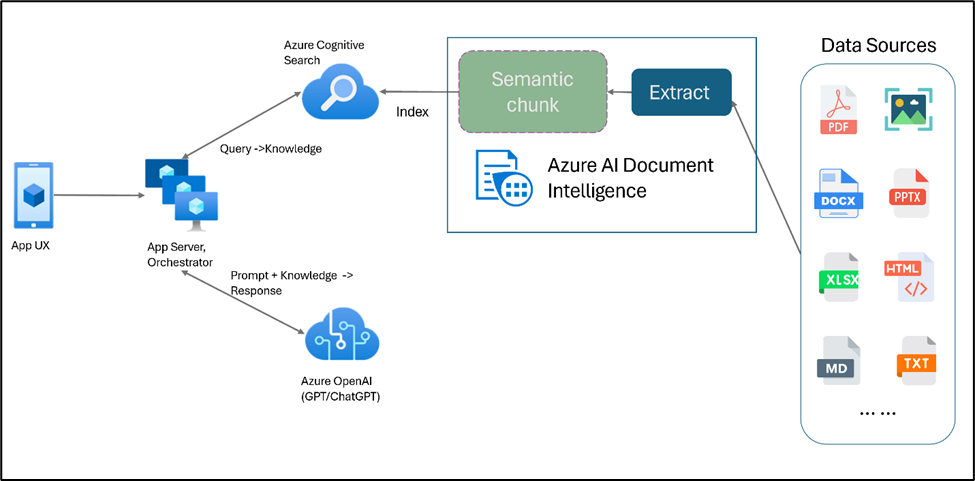
2. Complex Data Extraction using Document Intelligence and RAG
The team from Microsoft released an in-depth guide and solution for complex entity extraction using Azure Document Intelligence (DI) enhanced with RAG. The guide features code, real-world documents, and how they evaluated their solution.
3. Resource Management with Apache YuniKorn™ for Apache Spark™ on AWS EKS at Pinterest
Monarch, Pinterest’s Batch Processing Platform, was initially designed to support Pinterest’s ever-growing number of Apache Spark and MapReduce workloads at scale. During Monarch’s inception in 2016, the most dominant batch processing technology around to build the platform was Apache Hadoop YARN. Now, eight years later, we have made the decision to move off of Apache Hadoop and onto our next generation Kubernetes (K8s) based platform.

🎁 Bonus:
🔍 A Deep Dive Into GitHub Actions From Software Development to Data Engineering
🥇 Best resources for data architecture, data management, and data modeling
📅 Upcoming Events
11/4-8: PASS Data Community Summit
11/12-15: BUILD: The Dev Conference for AI & Apps
11/14: IMPACT 2024
11/19-21: OSA CON 24
Share an event with the community here or view the full calendar
Opportunities to get involved:
Share your story on how you got started in DE
Want to get involved in the community? Sign up here.
What did you think of today’s newsletter?
Your feedback helps us deliver the best newsletter possible.
If you are reading this and are not subscribed, subscribe here.
Want more Data Engineering? Join our community.
Want to contribute? Learn how you can get involved.
Stay tuned next month for more updates, and thanks for being a part of the Data Engineering community.