


Data Engineering Digest, April 2025

Hello Data Engineers,
Welcome back to another edition of the data engineering digest - a monthly newsletter containing updates, inspiration, and insights from the community.
Here are a few highlights from this month:
Greenfield Projects: Should You Build a Data Warehouse or Lakehouse?
Exploring European Cloud Alternatives
The Most Common Data Mistakes Companies Still Make
How LinkedIn Automates Multi-Hop Data Pipelines
AWS Adds Gen-AI Guidelines to Its Well-Architected Framework
What’s New in Apache Airflow 3: Release Highlights
Community Discussions
Here are the top posts you may have missed:
1. Greenfield: Do you go DWH or DL/DLH?
If you're building a data platform from scratch today, do you start with a DWH on RDBMS? Or Data Lake[House] on object storage with something like Iceberg?
It’s not uncommon for data engineers to be hired to build a new data platform because the business outgrew its current setup. In these scenarios, it’s helpful to understand how to make good architecture decisions in order to balance cost, performance, and future scalability.
💡 Key Insight
The data lake appears to have been superseded by the lakehouse as the majority of engineers say they would choose either a data warehouse or a data lakehouse depending on the requirements. See our previous discussion of this topic for a breakdown of the differences.
In order to help with requirements when starting a new data project, remember the “3 Vs”: volume, variety and velocity.
Volume: How much data do you currently have?
Variety: Is it structured (tabular), semi-structured (JSON, XML) or unstructured data (videos, images, audio)?
Velocity: Is it growing quickly? How quickly does it need to be ingested?
As a rule of thumb, if your data is under 10 TB and it’s mostly structured or semi-structured, or your team is early in its data maturity, a managed data warehouse is usually the simplest and most cost-effective choice. Most organizations fall under this first category. However, if you need to handle diverse data types, scale beyond a single machine, or prioritize flexibility over strict schemas, a data lakehouse may be a better fit. Keep in mind there are other factors like fine-grained access controls, compliance requirements, and whether your team has the skills to manage whichever architecture you choose.
2. Is there a European alternative to US analytical platforms like Snowflake?

As data engineers, we are increasingly having to plan for considerations like privacy, security, and even geopolitics. For many organizations, it’s no longer sufficient to just make infrastructure decisions based purely on performance or cost. The rise of data sovereignty concerns and regulations like GDPR are pushing teams in Europe to explore alternatives to U.S.-based cloud platforms. And it’s not just about compliance either - infrastructure choices are becoming more strategic as data engineers think about long-term control, minimizing lock-in, and staying aligned with local laws and expectations.
💡 Key Insight
The majority of the cloud market share in Europe is dominated by the three U.S.-based hyperscalers: AWS, Microsoft Azure, and GCP. However, there are several European cloud providers for those looking for alternatives. Exasol emerged as the top Snowflake/Databricks European alternative, though many engineers still favor open-source solutions for flexibility and cost control.
Even though U.S. hyperscalers operate EU data centers, some organizations prefer local providers to avoid extraterritorial data-access laws (e.g., the U.S. CLOUD Act). The CLOUD Act enacted in the U.S. in 2018 “allows federal law enforcement to compel U.S.-based technology companies via warrant or subpoena to provide requested data stored on servers regardless of whether the data are stored in the U.S. or on foreign soil.” It should be noted that countries around the world have developed similar laws and frameworks for extraterritorial data access (primarily for criminal investigations). Notably, the European Union adopted its own E-evidence law in 2023 to make it easier and faster for law enforcement to obtain electronic evidence.
👓 Related reading: Migrating from AWS to a European Cloud - How We Cut Costs by 62%
3. What’s the most common mistake companies make when handling big data?
Many businesses collect tons of data but fail to use it effectively. What’s a major mistake you see in data engineering that companies should avoid?
💡 Key Insight
Here are the top pitfalls from the community:
Hiring data analysts and data scientists to produce insights before establishing a solid data foundation.
Data engineers focusing on technology over business outcomes, leading to misaligned priorities and failed projects.
Over-engineering/pre-optimizing for small data sizes. Remember the 3 Vs (volume, variety, velocity)!
Lacking an overarching data strategy which causes sprawl and data quality issues.
Storing low-value/unused data which increases costs and is a potential security liability.
What do you think is the most common mistake companies make when it comes to data? Join the discussion.
Industry Pulse
Here are some industry topics and trends from this month:
1. Powering Apache Pinot ingestion with Hoptimator
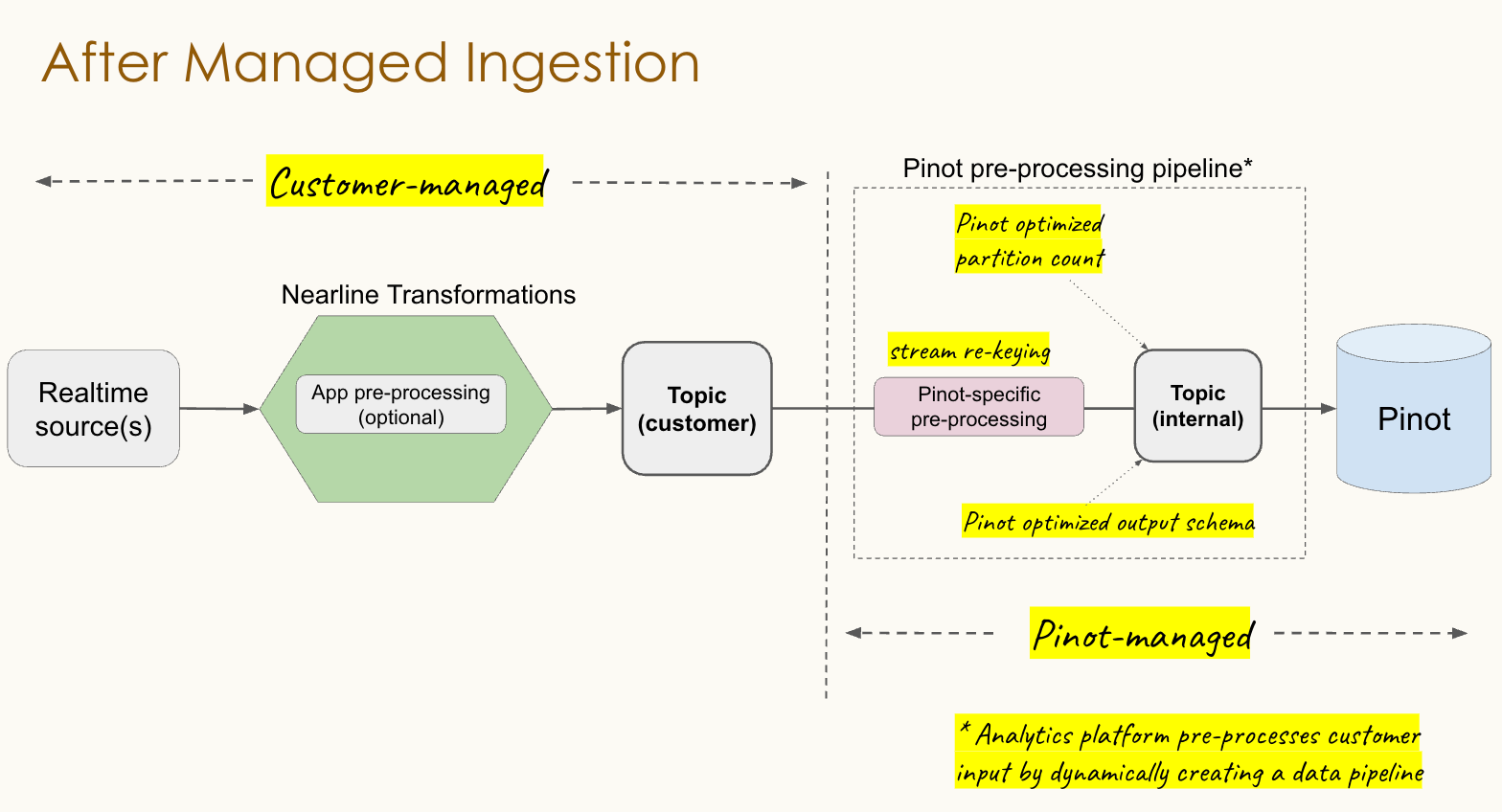
In a previous blog, we described a new open-source project, Hoptimator, which helps automate end-to-end multi-hop data pipelines. End-to-end multi-hop refers to Hoptimator's ability to plan pipelines across otherwise unrelated systems, and to wire up all the necessary components for the resulting pipelines to run. These pipelines are complex and touch many different systems, so building them manually can take weeks of effort. With Hoptimator, we can deploy new pipelines in minutes.
2. Announcing the AWS Well-Architected Generative AI Lens

The AWS Well-Architected Framework provides architectural best practices for designing and operating generative AI workloads on AWS. The Generative AI Lens provides a consistent approach for customers to evaluate architectures that use large language models (LLMs) to achieve their business goals. This lens addresses common considerations relevant to model selection, prompt engineering, model customization, workload integration, and continuous improvement. Specifically excluded from this lens are best practices associated with model training and advanced model customization techniques. We identify best practices that help you architect your cloud-based applications and workloads according to AWS Well-Architected design principles gathered from supporting thousands of customer implementations.
3. Apache Airflow® 3 is Generally Available!
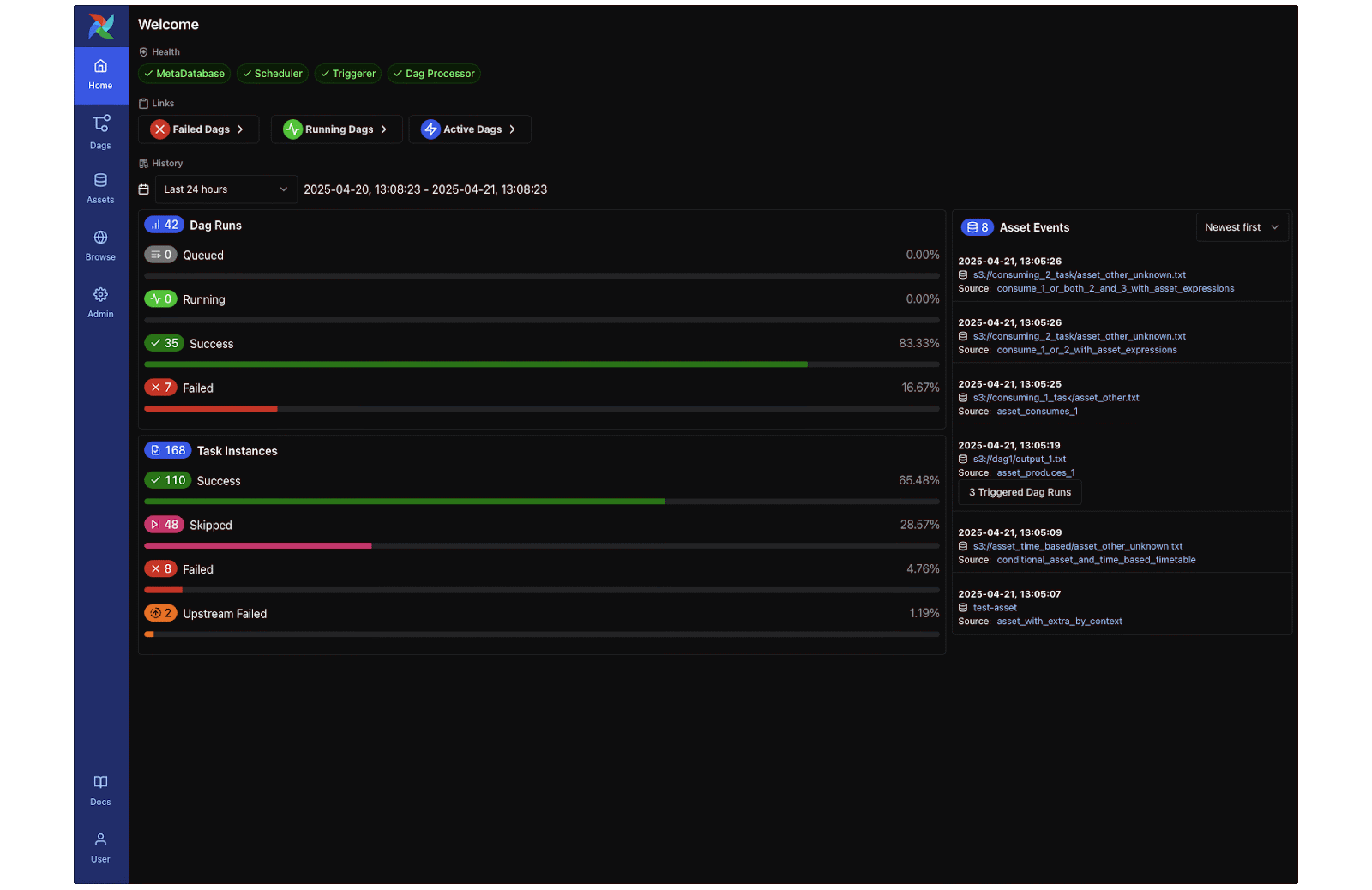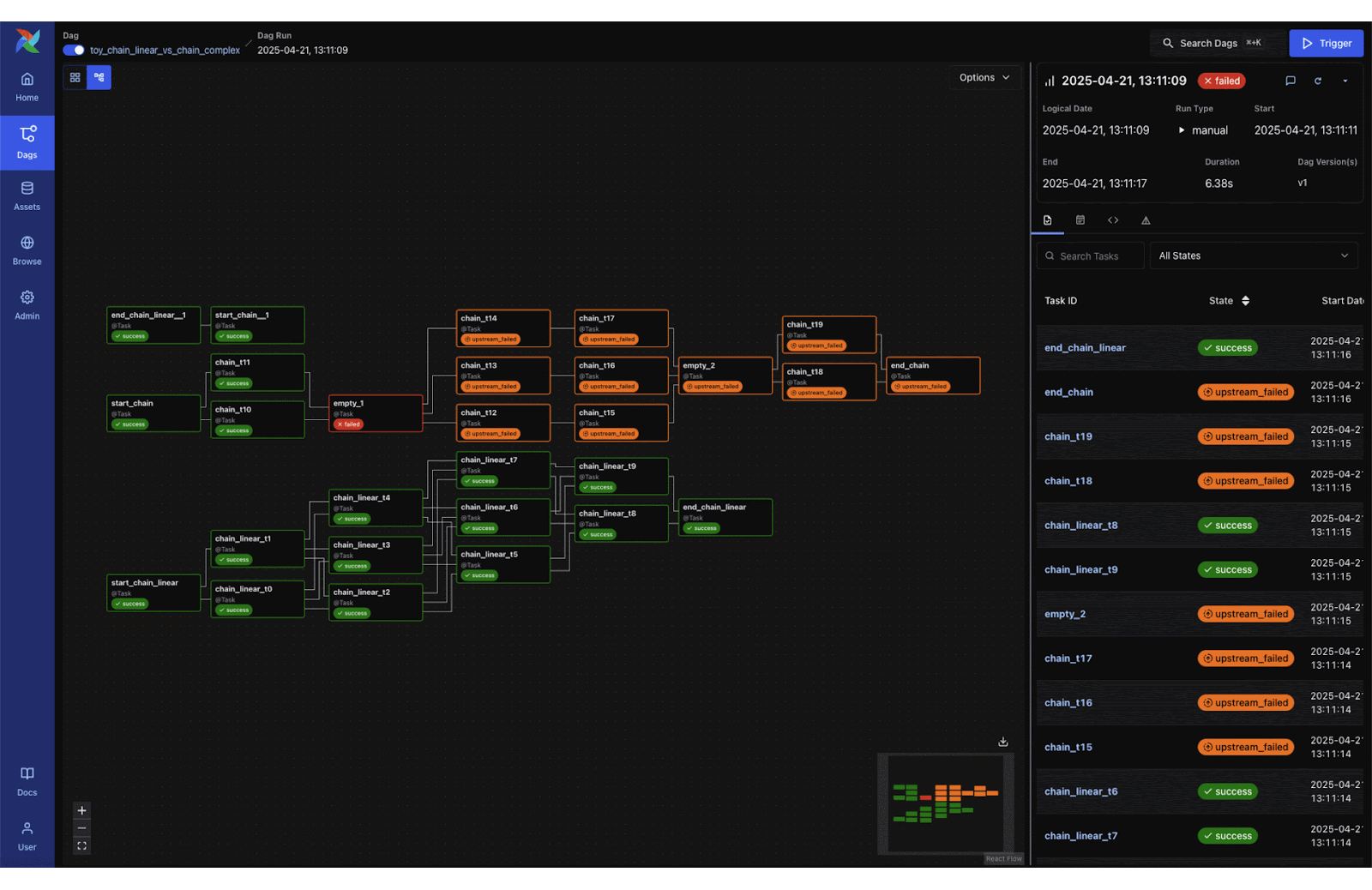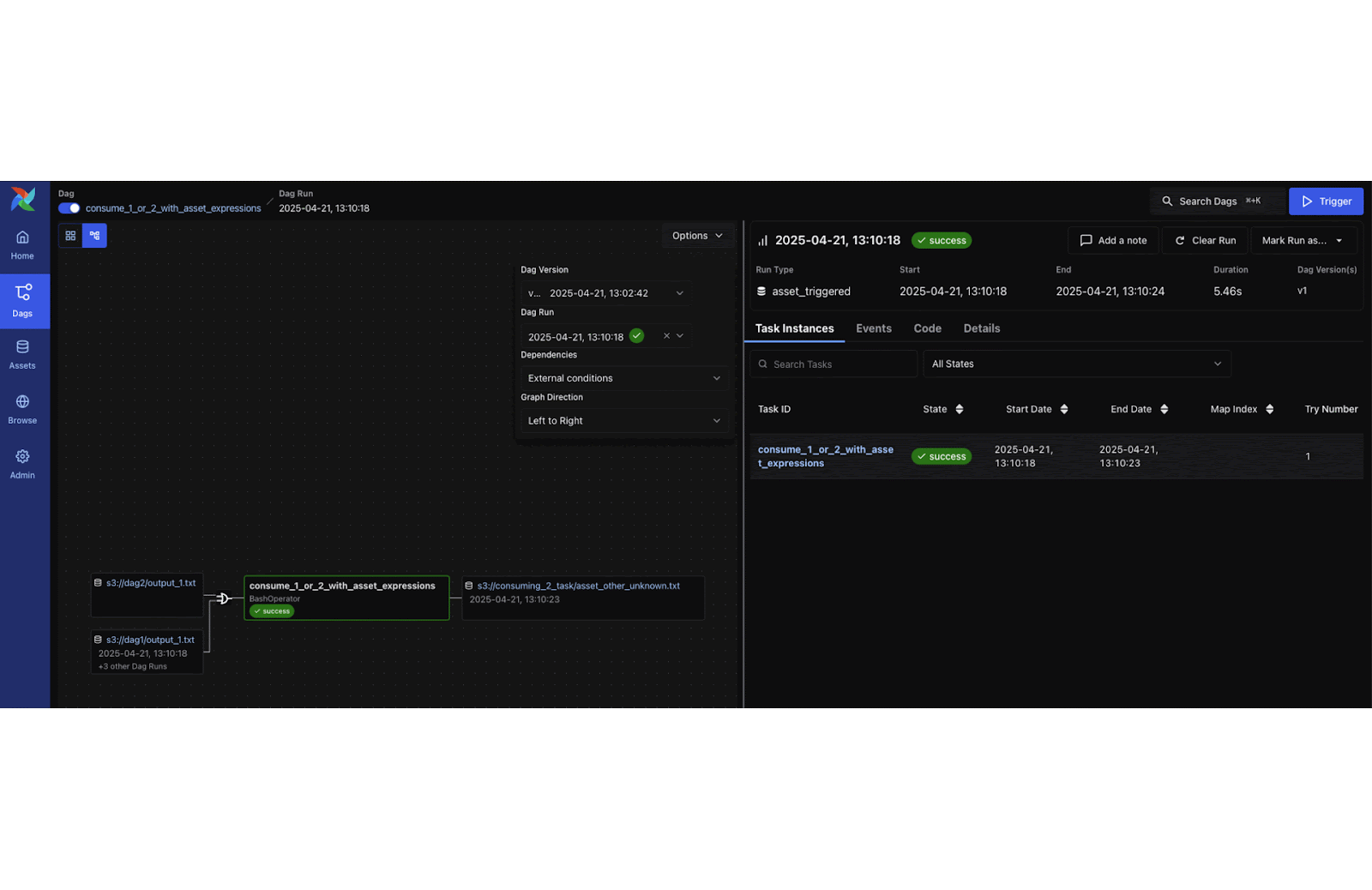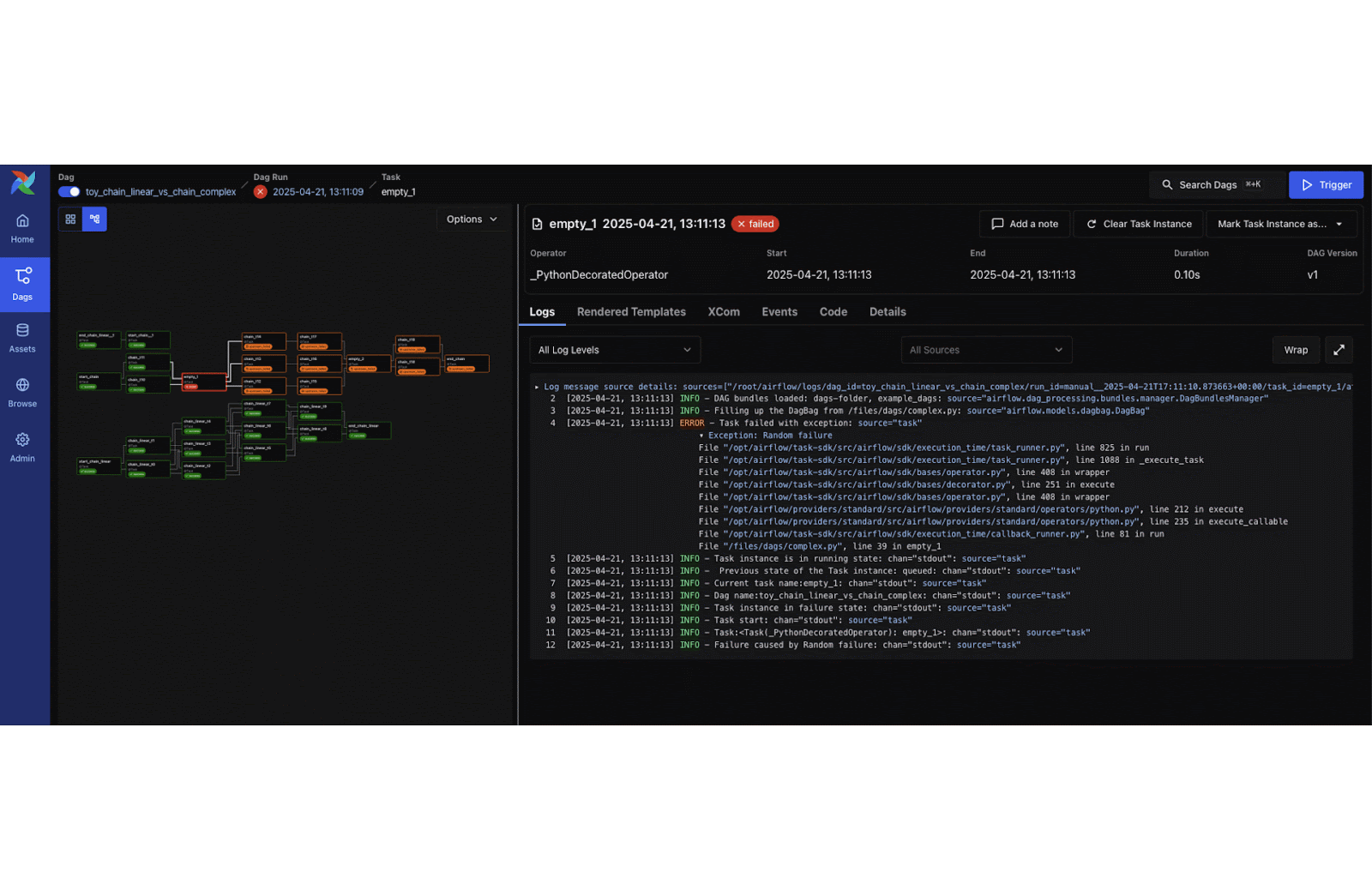
Airflow 3.0.0 was officially released, marking the largest Airflow update yet. Key new features include a modern React-based UI, DAG Versioning, and Event-Driven Scheduling (allowing DAGs to trigger on external events). Under the hood, Airflow 3 introduces a new Task SDK and execution interface for secure, scalable task execution across hybrid and multi-cloud environments.
🎁 Bonus:
🧊 [video] What is Iceberg, and why is everyone talking about it?
⚠️ Max severity RCE flaw discovered in widely used Apache Parquet
📅 Upcoming Events
Share an event with the community here or view the full calendar
Opportunities to get involved:
Want to get involved in the community? Sign up here.
What did you think of today’s newsletter?
Your feedback helps us deliver the best newsletter possible.
If you are reading this and are not subscribed, subscribe here.
Want more Data Engineering? Join our community.
Want to contribute? Learn how you can get involved.
Stay tuned next month for more updates, and thanks for being a part of the Data Engineering community.