


Data Engineering Digest, May 2025

Hello Data Engineers,
Welcome back to another edition of the data engineering digest - a monthly newsletter containing updates, inspiration, and insights from the community. This month’s edition is brought to you by Soda Data Quality:

Sign up for Soda’s launch week, June 9-13. Here’s a peek at what’s coming: the fastest and most accurate metrics observability, collaborative data contracts, transparent pricing with a free forever tier, and more. Learn more here.
Here are a few things that happened this month in the community:
Questioning the Bronze layer: all the data all the time?
The latest technologies/libraries for ETL pipelines
SQL editors data engineers LOVE
Netflix Engineering: BTS - Building a Robust Ads Event Processing Pipeline
Pinterest Engineering: Scaling experiment metric computing
DuckLake: SQL as a Lakehouse Format
Community Discussions
Here are the top posts you may have missed:
1. Is it really necessary to ingest all raw data into the bronze layer?
I have multiple data sources (Salesforce, HubSpot, etc.), where each object already comes with a well-defined schema. In my ETL pipeline, I use an automated schema validator: if someone changes the source data, the pipeline automatically detects the change and adjusts accordingly… Curious to hear from others doing things manually or with lightweight infrastructure — is skipping unused fields in Bronze really a bad idea if your schema evolution is fully automated?
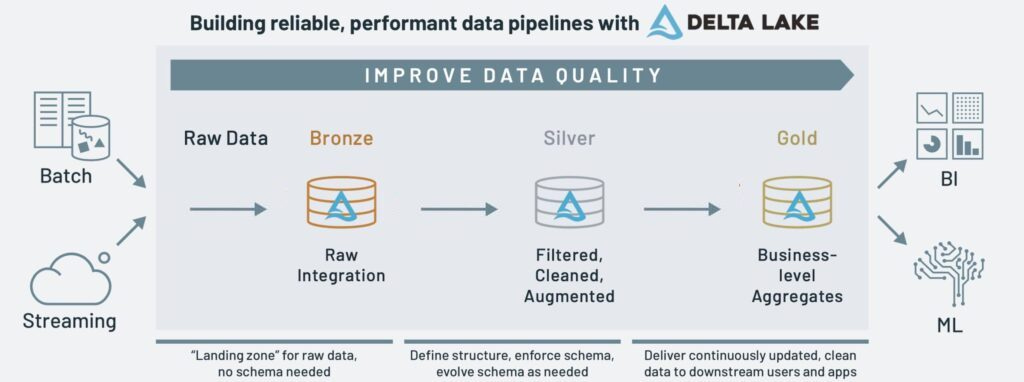
This question sparked a healthy debate around “best practices” in medallion architecture as schema evolution automation is becoming more common. Should you still store all the data even if it’s not technically necessary?
💡 Key Insight
The verdict: store all raw fields in your Bronze layer, even those you think you’ll never use because storage is inexpensive and it’s impossible to fully anticipate what you may need in the future. By preserving every incoming record and its history, you will avoid costly backfills when schemas change, easily adapt to changing metric definitions, and you’ll be able to ensure you won’t lose access to data that your sources can no longer provide.
Another benefit of a complete raw archive is a built-in audit trail that simplifies debugging and meets compliance or security protocols. When every record and its original schema are available, you gain full historical context for analysis, troubleshooting, and regulatory reporting without extra engineering effort.
2. What are the newest technologies/libraries/methods in ETL Pipelines?
The ETL space is constantly evolving and this month the community highlighted several tools designed to boost performance, reduce boilerplate, and support modern data formats.
Here is a similar post we shared back in March 2024: Favorite Python Library?
💡 Key Insight
Here are the community’s top picks for ETL tools and libraries:
ConnectorX: Fastest library to load data from DB to DataFrames in Rust and Python.
dltHub: Lightweight Python code to move data.
Loguru: Python logging made (stupidly) simple.
uv: An extremely fast Python package and project manager, written in Rust.
PyIceberg: A Python implementation for accessing Iceberg tables, without the need of a JVM.
Pyrefly: A fast type checker and IDE for Python (recently open-sourced by Meta).
SQLMesh: Scalable and efficient data transformation framework - backwards compatible with dbt.
How do you typically keep up with the latest tools and technologies? Join the conversation.
3. Which SQL editor do you use?
SQL is still the backbone for many data engineering workflows so choosing an editor that will make working with SQL easier can be a huge quality of life improvement.
💡 Key Insight
The results were almost evenly split between free and paid tools and between general IDEs with a SQL extension vs SQL-specific editors.
Top Choices:
[Free] Dbeaver (community edition)
[Free] SSMS (SQL Server & Azure only) + [Paid] RedGate SQL Prompt
Honorable Mentions:
[Paid] TablePlus
[Free] DBVisualizer
Industry Pulse
Here are some industry topics and trends from this month:
1. Behind the Scenes: Building a Robust Ads Event Processing Pipeline

In a digital advertising platform, a robust feedback system is essential for the lifecycle and success of an ad campaign. This system comprises of diverse sub-systems designed to monitor, measure, and optimize ad campaigns. At Netflix, they embarked on a journey to build a robust event processing platform that not only meets the current demands but also scales for future needs. This blog post delves into the architectural evolution and technical decisions that underpin their Ads event processing pipeline.
2. 500X Scalability of Experiment Metric Computing with Unified Dynamic Framework

Pinterest relies heavily on experimentation to guide product and business decisions, with thousands of experiments generating insights daily. By the end of 2024, over 1,500 user-defined metrics are computed each day. However, as experimentation scaled, issues like data ingestion delays, backfill challenges, and scalability bottlenecks emerged.
To solve this, Pinterest introduced the Unified Dynamic Framework (UDF) - a scalable and resilient system that streamlined metric computation. UDF eliminated upstream dependencies, sped up metric delivery, and significantly reduced the time and effort needed to build data pipelines. It enabled engineers to focus on metric innovation rather than infrastructure, supporting 100X the metrics now and scaling toward 500X in the future.
3. DuckLake: SQL as a Lakehouse Format

This month DuckDB announced a new lakehouse format. DuckLake simplifies lakehouses by using a standard SQL database for all metadata, instead of complex file-based systems, while still storing data in open formats like Parquet. This makes it more reliable, faster, and easier to manage.
🎁 Bonus:
📅 Upcoming Events
6/2-6/5: Snowflake Summit 2025
6/9-6/12: Data + AI Summit by Databricks
Share an event with the community here or view the full calendar
Opportunities to get involved:
Want to get involved in the community? Sign up here.
What did you think of today’s newsletter?
Your feedback helps us deliver the best newsletter possible.
If you are reading this and are not subscribed, subscribe here.
Want more Data Engineering? Join our community.
Want to contribute? Learn how you can get involved.
Stay tuned next month for more updates, and thanks for being a part of the Data Engineering community.
Nicely thought out piece, capturing some of the latest industry thinking.